AI Agent 面试题第四弹:MCP、Chrome DevTools、CDP 会话复用
content
01、MCP 是什么,解决了什么问题
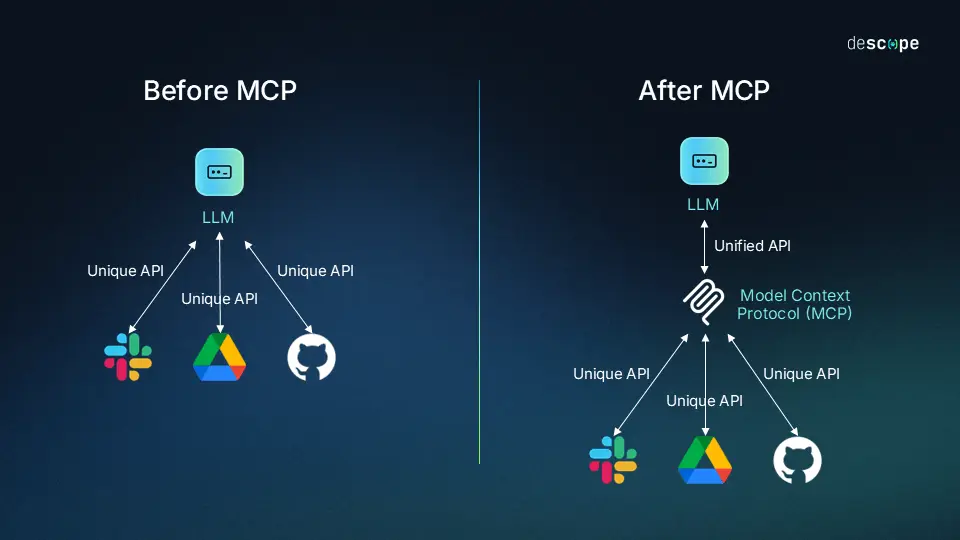
MCP 全称 Model Context Protocol,是 A 厂在 2024 年底推出的开放协议,一句话概括就是:给 AI 应用和外部工具之间定了一套标准通信接口。
为什么需要这个协议?
没有 MCP 之前,每个 AI 应用想接入一个新工具就得自己写一套定制代码,你写你的,我写我的,重复劳动。
Claude Code 要接入 GitHub,写一套;Qoder 要接入 GitHub,再写一套——干的活一模一样,但代码完全不能复用。
有了 MCP 就不一样了,GitHub 官方只需要写一个 MCP Server,所有支持 MCP 的 AI 应用直接接入,和当年 USB 统一接口一个道理。
它具体解决了哪几个问题
说白了就三件事。
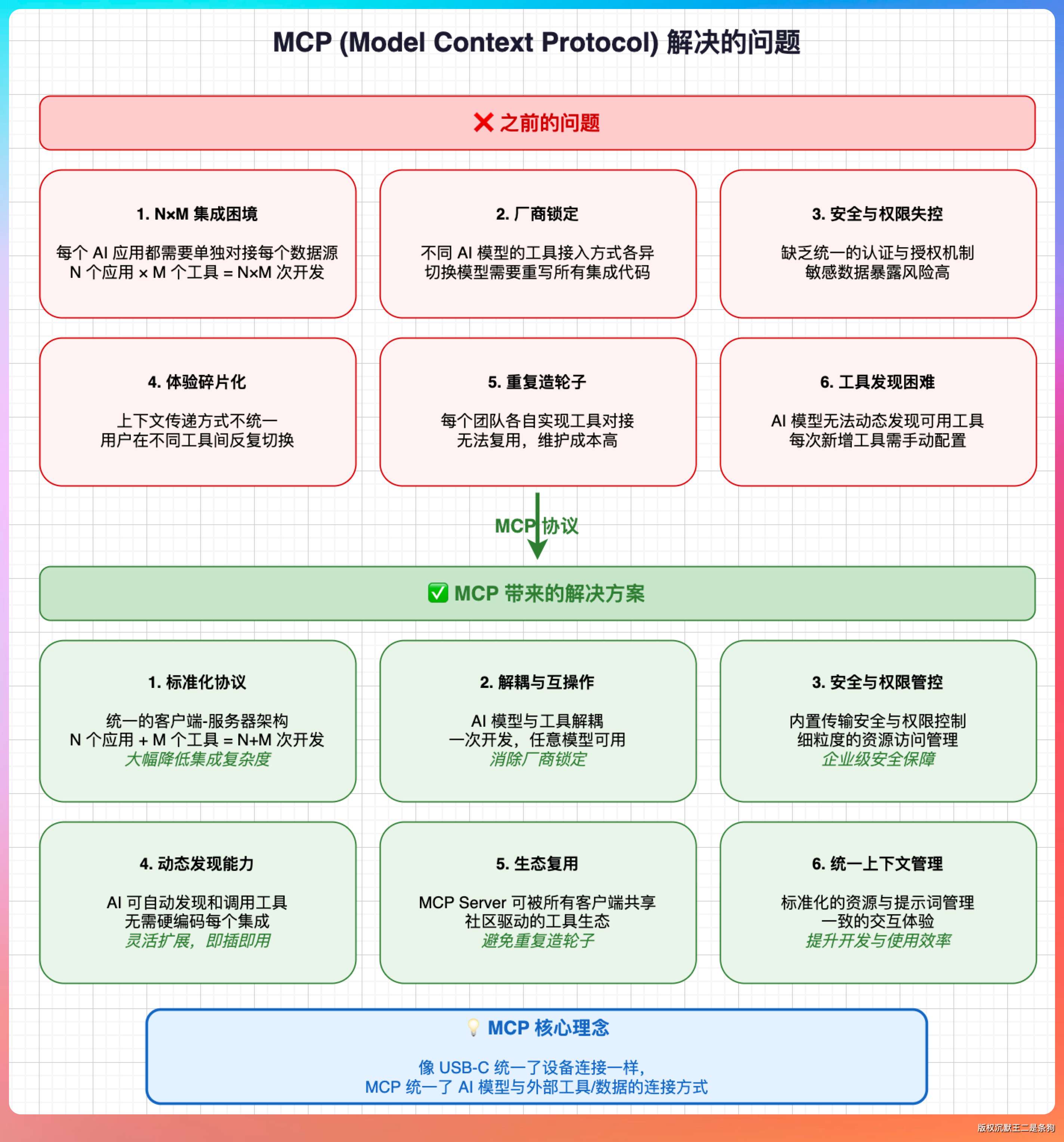
工具发现——Host 启动 MCP Server 后,调一次 tools/list 就知道这个 Server 能干啥,不用提前硬编码。
工具调用——统一走 tools/call 接口,不管底层是 Git 操作、浏览器操控还是数据库查询,调用方式一模一样,对 Agent 来说完全无感。
数据访问——resources/list 加 resources/read 让 Server 暴露可读取的数据源,LLM 需要上下文的时候直接拿。
02、MCP 的 stdio 传输和 Streamable HTTP 传输有什么区别
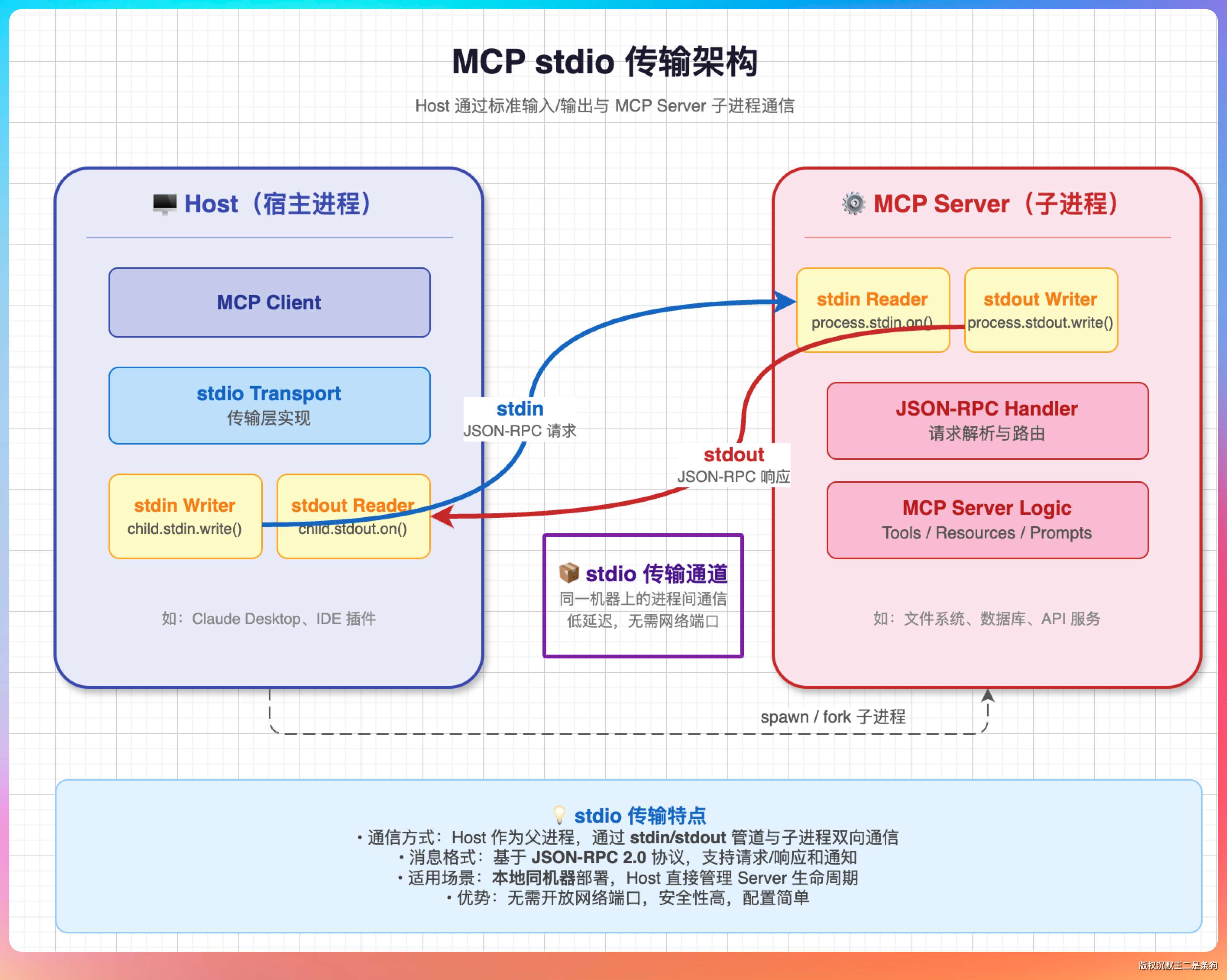
stdio 就是标准输入输出。Host 把 MCP Server 当子进程启动,通过 stdin 发 JSON-RPC 消息,stdout 接收响应。Server 的生命周期完全由 Host 控制——Host 一退出,stdin 就 EOF 了,Server 跟着结束。
适合本地工具,比如 chrome-devtools-mcp、mcp-server-git 这些。
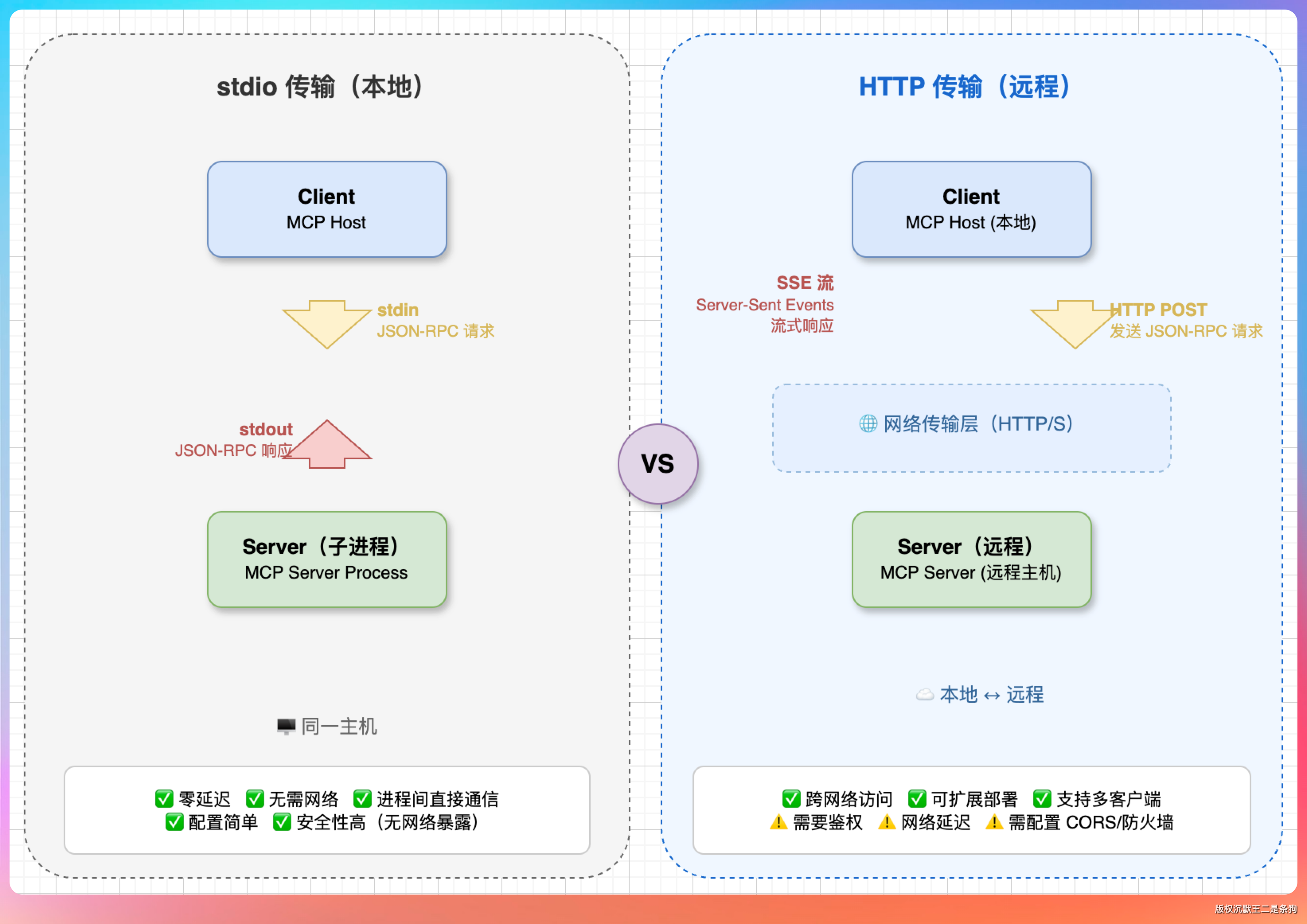
Streamable HTTP 走的是网络。Host 通过 HTTP POST 发 JSON-RPC 请求,Server 用 SSE 流式返回响应。Server 是独立部署的远程服务,跟 Host 没有生死绑定,你关了客户端,Server 还活着。
适合云端工具、团队共享的 MCP Server。
配置文件里怎么区分?也简单,有 command 字段就走 stdio,有 url 字段就走 HTTP,PaiCLI 自己判断。
03、MCP 的 JSON-RPC 通信协议是怎么工作的
用的是 JSON-RPC 2.0,消息就三种。
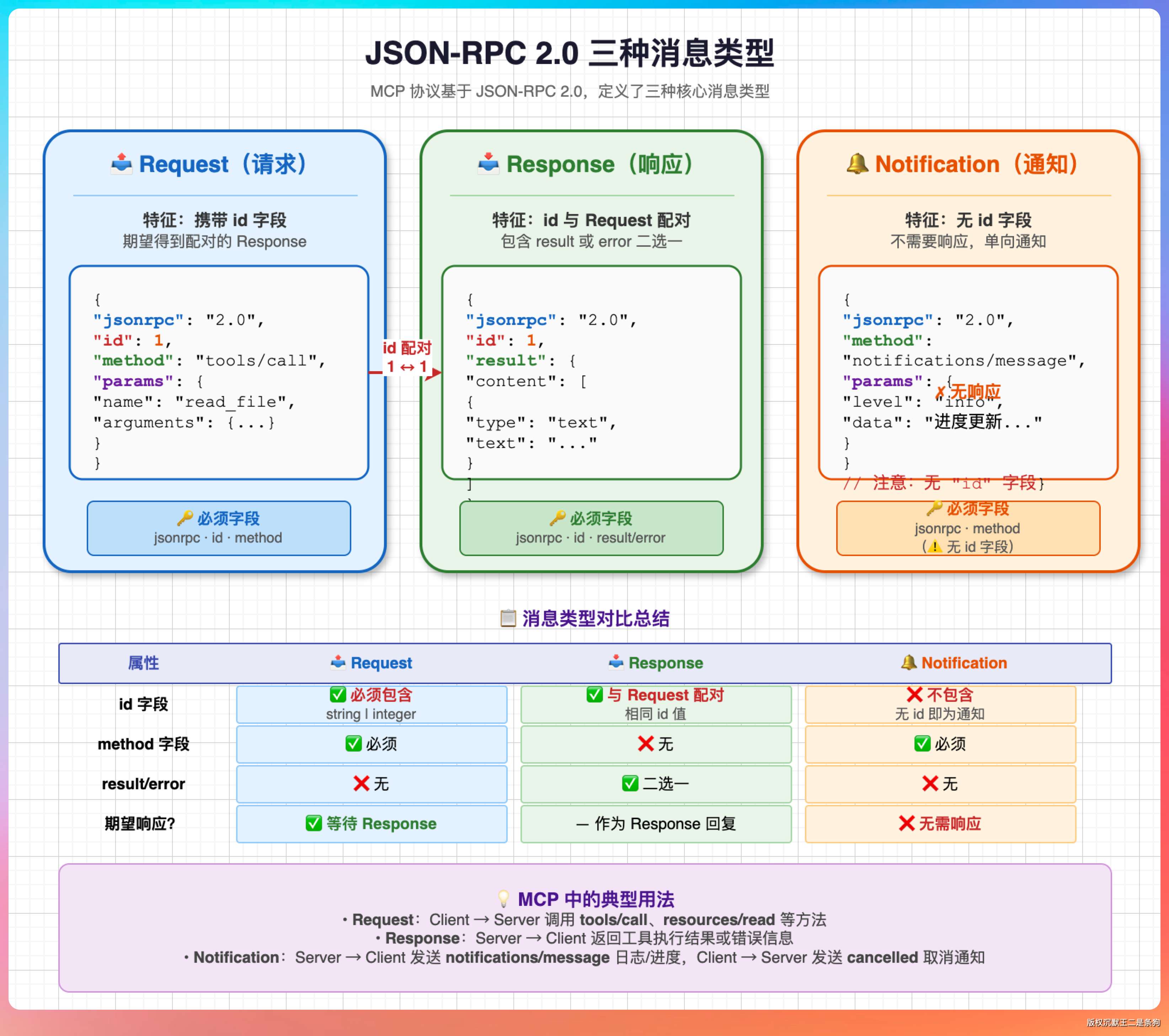
**Request,**带 id,需要对方响应。比如 tools/list 请求,id 是 1,Host 发出去之后等 Server 返回 id 同样是 1 的 Response。
**Response,**id 和 Request 配对。Server 收到 id 为 1 的请求,处理完了原样回一个 id 为 1 的响应,Host 拿着 id 一对,就知道这是哪个请求的结果了。
**Notification,**没有 id,不需要响应,单向通知。比如 Server 工具列表变了,推一条 tools/list_changed,Host 收到后自己去重新拉一遍就行。
请求和响应的配对怎么实现的
核心就是一个 ConcurrentHashMap,key 是自增的请求 id,value 是 CompletableFuture。
发请求时用自增 id 注册一个 Future,收到响应时按 id 找到对应的 Future 把结果填进去就完成配对了。同时还有超时兜底,超过一定时间没收到响应就自动报超时异常,防止 Future 永远挂着。
完整的通信生命周期长这样:
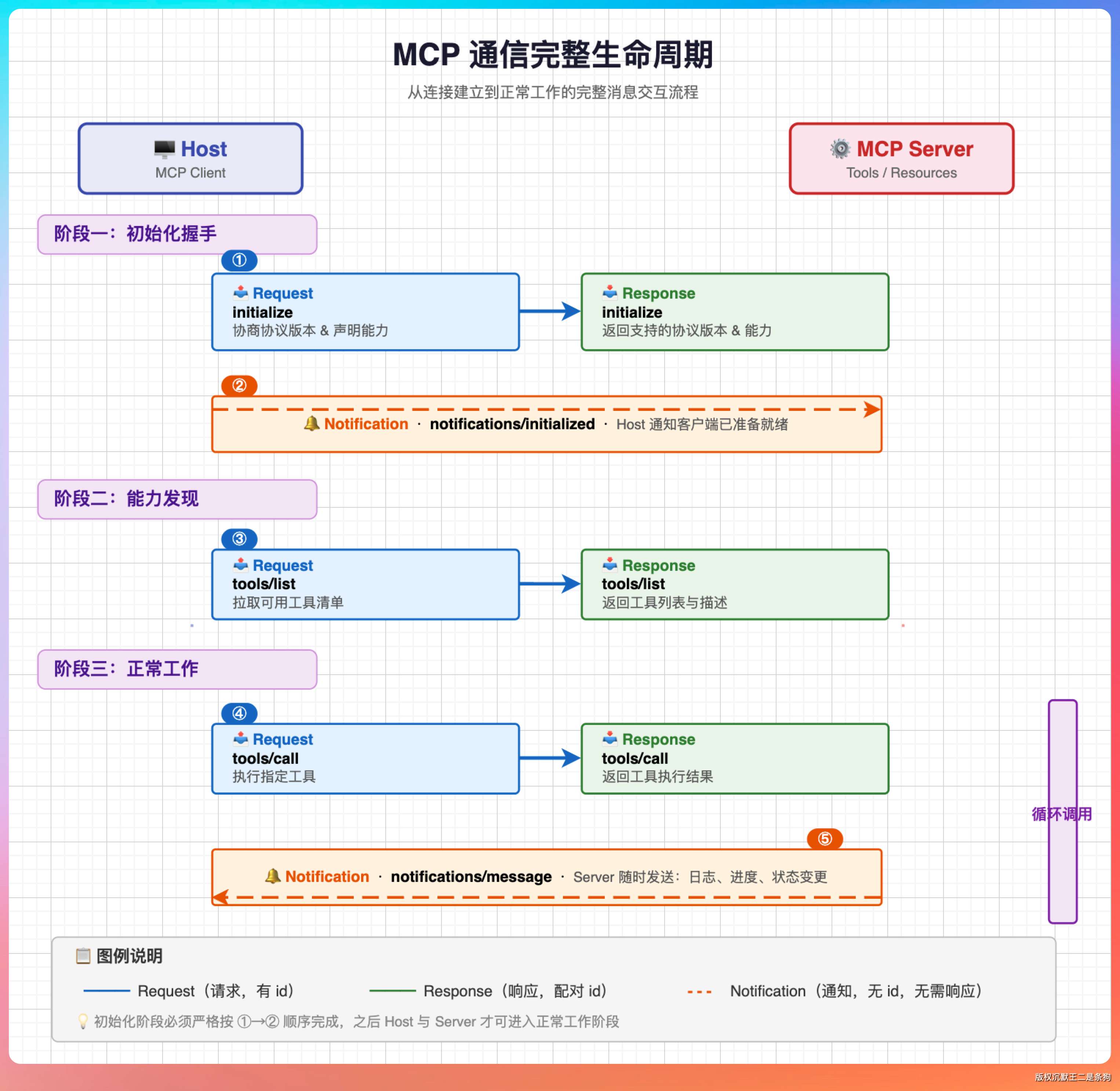
Host 先发 initialize 协商版本和能力 → Server 回应 → Host 发 initialized 表示"我准备好了" → 调 tools/list 拉工具清单 → 然后就进入正常工作状态,用 tools/call 执行工具 → Server 有变化随时推 notification。
为什么这样回答:JSON-RPC 本身不难,面试官考的是你有没有自己写过。提到 ConcurrentHashMap + CompletableFuture 做请求-响应配对,就说明你不是只会调 SDK,而是真正摸过底层通信。
04、MCP 工具注册到 Agent 后,命名空间怎么设计的
PaiCLI 给每个 MCP 工具注册的时候,用的是 mcp__server名__tool名 这种格式。比如 chrome-devtools 这个 Server 的 navigate_page 工具,注册完就叫 mcp__chrome-devtools__navigate_page。

为什么用双下划线
因为工具名本身就带单下划线,像 navigate_page、take_screenshot。
如果用单下划线做分隔符,就分不清 server 名在哪结束、tool 名从哪开始。双下划线在 MCP 工具名里不会出现,是天然安全的分隔符。
这个命名空间的设计带来的好处也很实在:
- 避免冲突,两个 Server 都有叫 search 的工具,加了前缀就不会混淆。
- 安全隔离,审批策略可以按前缀做,比如用户说"放行整个 chrome-devtools",匹配前缀即可。
- LLM 可理解,LLM 看到 mcp__chrome-devtools__navigate_page,直接就能判断这是浏览器相关操作。
05、MCP 的 resources 是什么,和 tools 有什么区别
简单说,Tools 是能干活的,有输入参数、会改变状态;Resources 是能读的,通过 URI 访问,返回内容,只读不写。你可以把 Tools 理解成 POST 端点,Resources 理解成 GET 端点。
但实际使用中有个问题:LLM 不能直接调 resources/read,因为 Function Calling 协议里只有 tools 的概念,没有 resources。
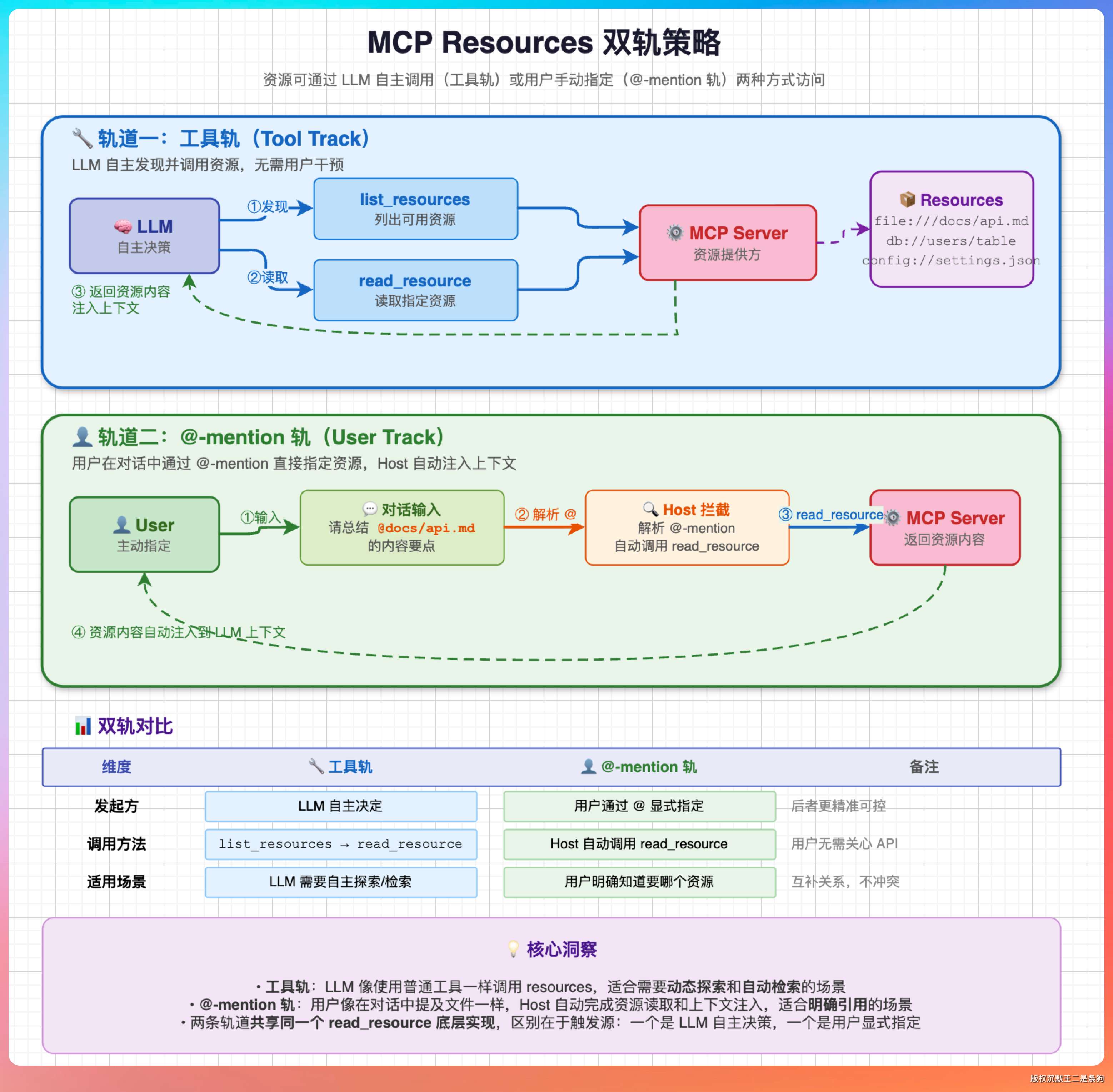
所以 PaiCLI 做了两件事来填这个坑。
一是把 resources 包装成工具。给每个支持 resources 的 Server 自动注册两个虚拟工具——list_resources 和 read_resource。LLM 可以像调普通工具一样调用它们,先查有哪些资源,再按 URI 读取内容。
二是支持用户直接 @ 指定。用户在输入里写 @server:protocol://path,PaiCLI 在提交给 Agent 之前自动把资源内容展开塞进去,不经过 LLM 决策。
两种方式各有适用场景:LLM 需要主动探索数据的时候走工具,用户已经知道要读什么资源的时候直接 @ 指定。
06、MCP Server 启动失败或超时怎么处理
这个问题实际开发中真的经常遇到,PaiCLI 做了好几层兜底。
首先,initialize 设了 60 秒超时,不能让一个 Server 卡住把整个 Agent 的启动流程都堵了。
然后,多个 Server 是并行启动的,后台线程各干各的,不会互相等。
启动期间每 5 秒打印一次等待状态,告诉用户"某某 Server 还没就绪",别让人干等着不知道发生了什么。
最后还有个 /mcp restart 命令,某个 Server 挂了可以单独重启,不用全部重来。
07、Chrome DevTools MCP 能干什么,和 web_fetch 怎么分工
Chrome DevTools MCP 是 Google 官方出的 MCP Server,一口气提供了 28 个浏览器操作工具。干嘛用的?就是让 LLM 能像真人一样操作浏览器——打开网页、填表单、点按钮、截图、抓网络请求,你能干的它都能干。
已经有 web_fetch 了,为什么还要Chrome DevTools MCP
web_fetch 本质就是一个 HTTP 请求,只能拿到静态 HTML。碰到 SPA、JS 渲染的页面、有防爬的站点,就彻底抓瞎了。浏览器 MCP 不一样,它是真正跑了一个 Chrome 实例,JavaScript 照跑,登录态照保,什么页面都拿得到。
PaiCLI 在 system prompt 里有一张决策表,LLM 会根据任务特征自己判断走哪条路:静态页面走 web_fetch,便宜又快;SPA 和 JS 渲染走浏览器的 take_snapshot;防爬站点也走浏览器;需要登录的页面走浏览器加 CDP 会话复用;需要填表提交的走 fill_form + click。
08、CDP 会话复用是怎么实现的
Chrome DevTools MCP 默认是 isolated 模式,每次启动都创建一个全新的浏览器 profile,没有任何登录态。
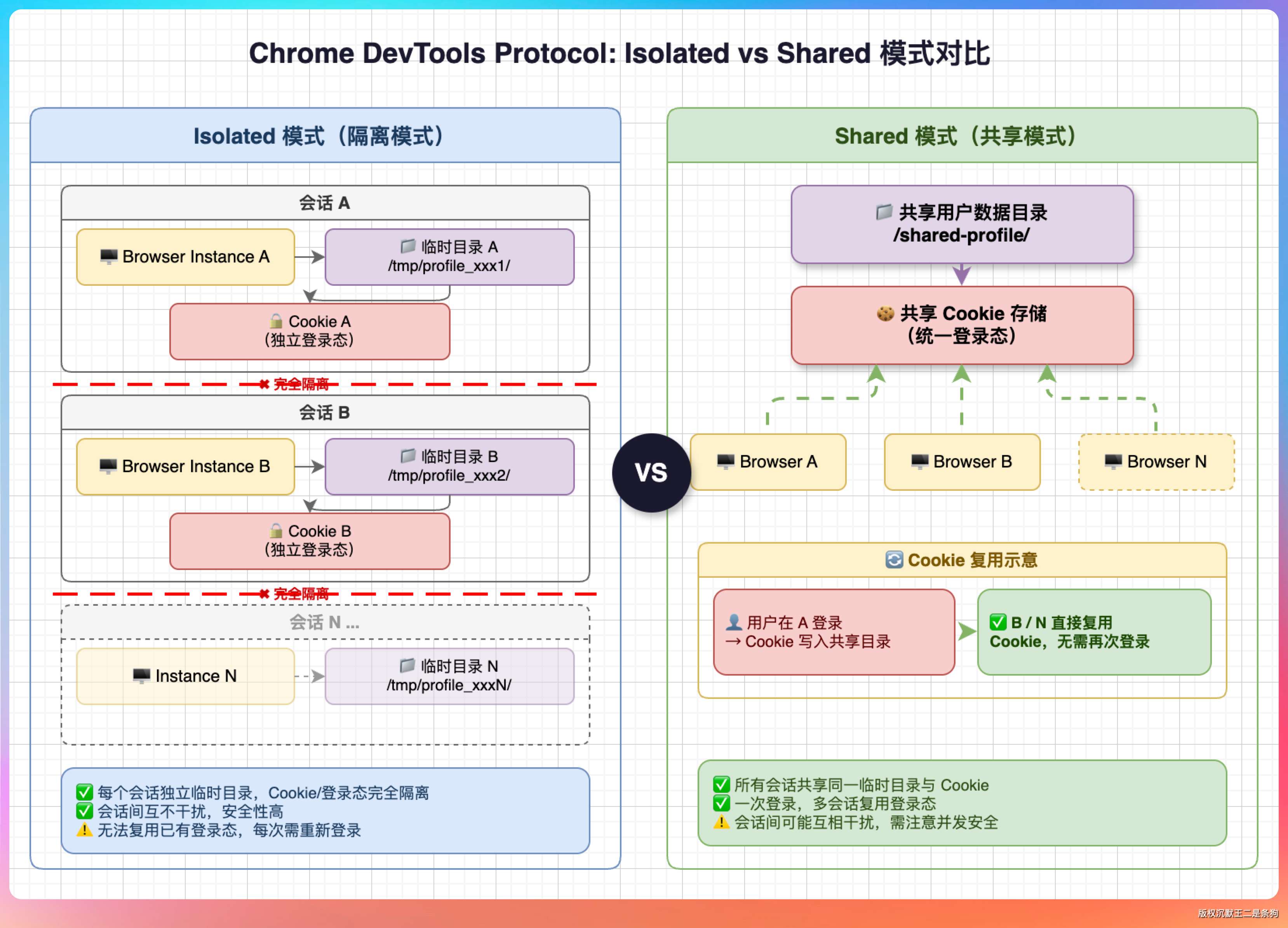
所以 PaiCLI 做了 CDP(Chrome DevTools Protocol)会话复用。
流程是这样的:用户在自己的 Chrome 里正常登录各种网站,然后在 PaiCLI 里执行 /browser connect,把 MCP 从 isolated 模式切到 autoConnect 模式。MCP Server 连接到用户已有的 Chrome 实例,复用全部登录态。这样 Agent 就能直接访问已登录的页面了。
09、MCP 的通知机制有几种?
三种:tools/list_changed 工具列表变了、resources/list_changed 资源列表变了、resources/updated 某个资源的内容更新了。
PaiCLI 收到 tools/list_changed 就自动重新拉取工具列表,收到 resources 相关的通知就清掉对应缓存,保持数据新鲜。
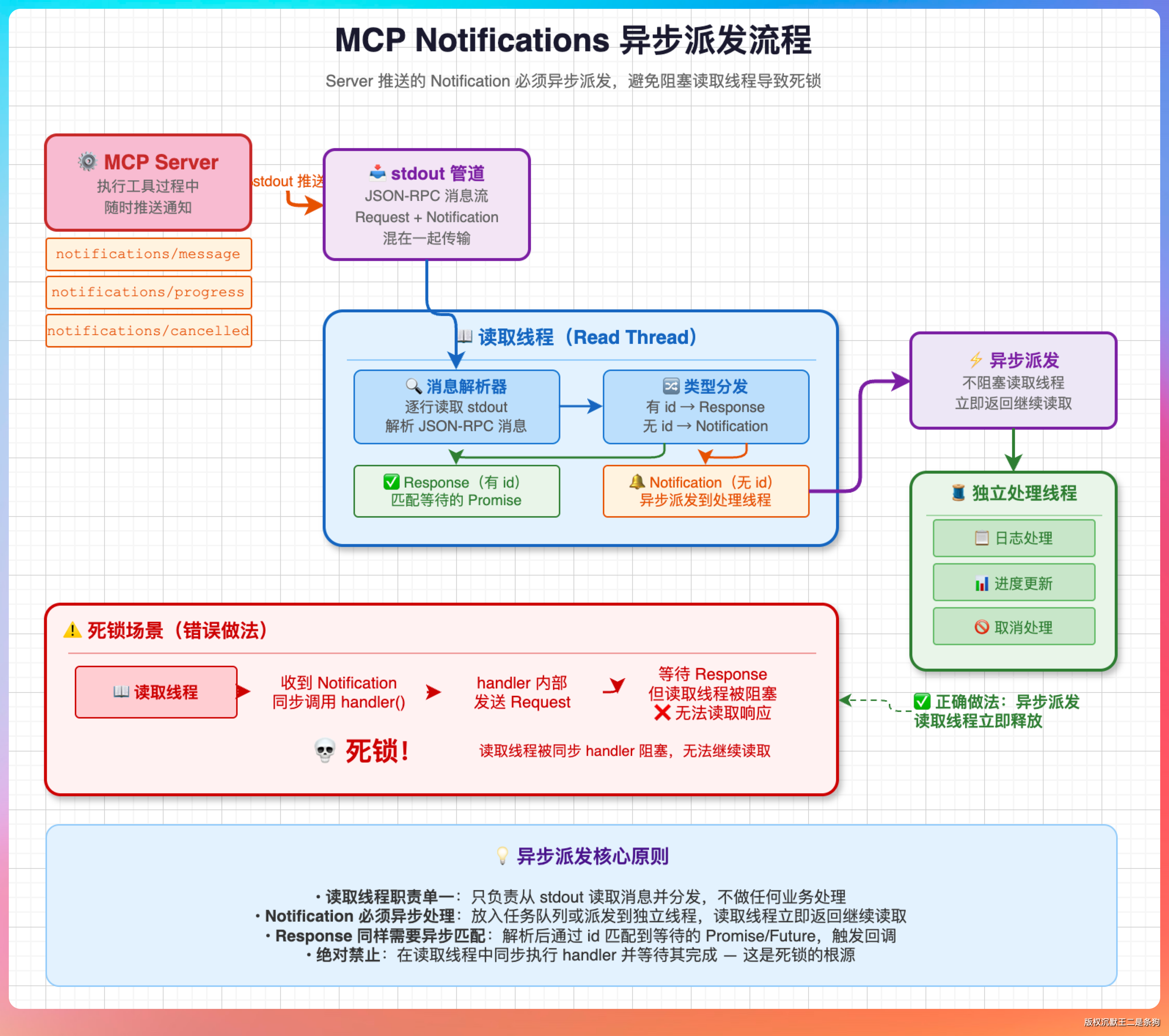
通知的 handler 为什么要异步执行
如果通知处理逻辑直接跑在消息读取线程里,处理逻辑内部要是发了一个 JSON-RPC 请求并等响应,就会死锁。
因为读取线程被占着,新的响应进了缓冲区但没人读,等待的响应永远读不到。典型场景就是 Server 推送 tools/list_changed,处理逻辑要调 tools/list 重新拉工具列表,结果自己等自己,死锁了。
所以 PaiCLI 用一个独立的单线程做异步派发,通知处理和消息读取完全隔离,彻底避免了这个问题。
10、MCP 的 tools/call 返回结果怎么处理
tools/call 返回的是一个 content 数组,每个元素有 type 字段,主要三种:text、image、resource。
text 最简单,直接拼成字符串当 tool message 返回给 LLM 就行。
image 类型稍微复杂一些。先解码 base64,处理成功就生成图片附件,下一轮对话里发给 LLM。如果处理失败了,比如图片太大或者格式不支持,就降级为文本提示,告诉 LLM 用 take_snapshot 获取 DOM 文本快照。
resource 类型就是提取文本内容,拼到 text 结果里一起返回。
如果工具执行失败了,isError 为 true,整个结果会包装成"MCP 工具返回错误"的格式,LLM 看到后知道调用失败了,可以决定重试还是换个思路。
11、MCP 和 Function Calling 有什么关系
这俩经常被搞混,但其实分工很清楚。
Function Calling 是 LLM API 层的协议,干两件事:告诉 LLM"你有哪些工具能用",以及让 LLM 说"我要调这个工具"。
MCP 是工具提供方的协议,解决的是"工具从哪来、长什么样、怎么执行"。
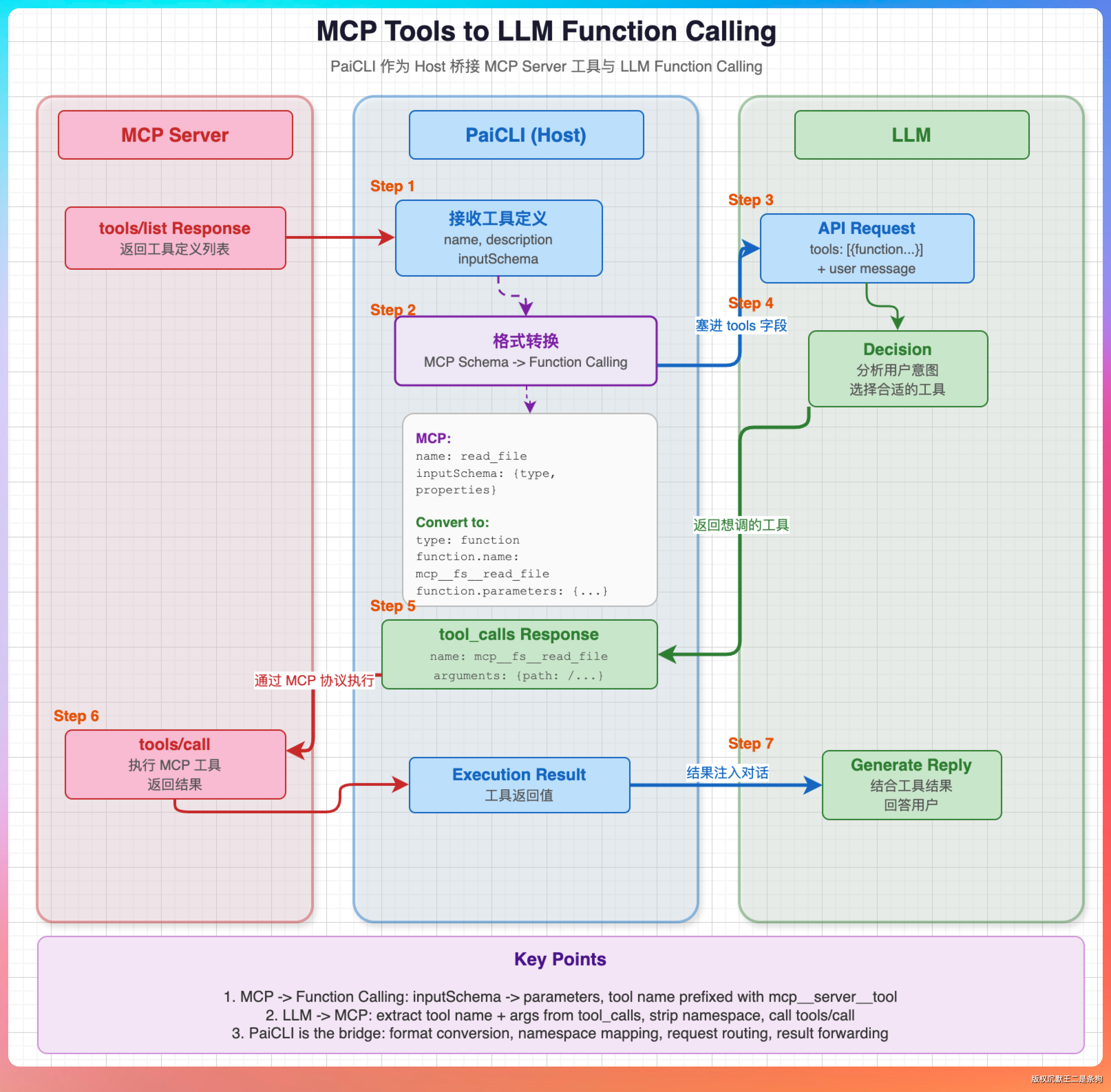
串起来看就清楚了:MCP Server 通过 tools/list 返回工具定义 → PaiCLI 把这些定义转成 Function Calling 格式 → 塞进 LLM 请求的 tools 字段 → LLM 返回 tool_calls 说"我要调某个 MCP 工具" → PaiCLI 通过 MCP 的 tools/call 去执行 → 结果再喂回给 LLM。
一句话总结:MCP 管"工具从哪来",Function Calling 管"LLM 怎么选"。两个协议各管一段,合在一起才是完整的工具调用链路。
12、MCP 的 schema 清洗是什么,为什么需要
MCP Server 返回的工具参数是标准 JSON Schema,但 LLM 不是 JSON Schema 解析器,有些复杂结构它处理不好。
典型的有三个问题:
$ref引用,JSON Schema 允许用$ref指向别处的定义,但 LLM 不会去"查字典",看到$ref就懵了,生成的参数大概率对不上。anyOf/oneOf联合类型,参数可以是 string 也可以是 number,LLM 选错类型的概率很高。- 超长
description,有些 MCP Server 的工具描述写了几千字,把整个 API 文档塞进去了,LLM 被信息淹没反而搞不清核心参数。
所以 PaiCLI 在注册工具时会自动做一轮清洗:$ref 直接展开或移除,anyOf/oneOf 转成自然语言描述放到 description 里,超长描述做截断。清洗后的 schema 对 LLM 更友好,参数生成的准确率也更高。
13、如果让你设计一个 MCP Server,你会怎么做
先确定传输方式。工具跑在用户本地就选 stdio,跑在云端给多人共享就选 Streamable HTTP。
然后在 initialize 握手时声明能力——Server 支持 tools、resources 还是 prompts,在握手阶段明确告诉 Host。
接下来是设计工具,这步最关键。每个工具职责单一,参数 schema 严格定义。工具描述是写给 LLM 看的,要说清楚"这个工具干什么、什么时候该用、什么时候不该用",描述质量直接影响 LLM 的调用准确率。
错误处理。工具执行失败要返回 isError: true,加上有意义的错误信息,LLM 才能判断下一步该怎么做。
生命周期管理。stdio 模式下要正确处理 stdin EOF 并清理资源,HTTP 模式下要处理 session 超时和并发请求。
最后是安全标注。如果 Server 能访问敏感数据或执行危险操作,在 tool description 里标注出来。Host 端的安全机制可以根据描述里的关键词调整审批策略。