AI Agent 面试题第六弹:TUI 渲染、LSP 诊断注入、Git 快照、Runtime API 13 题
content
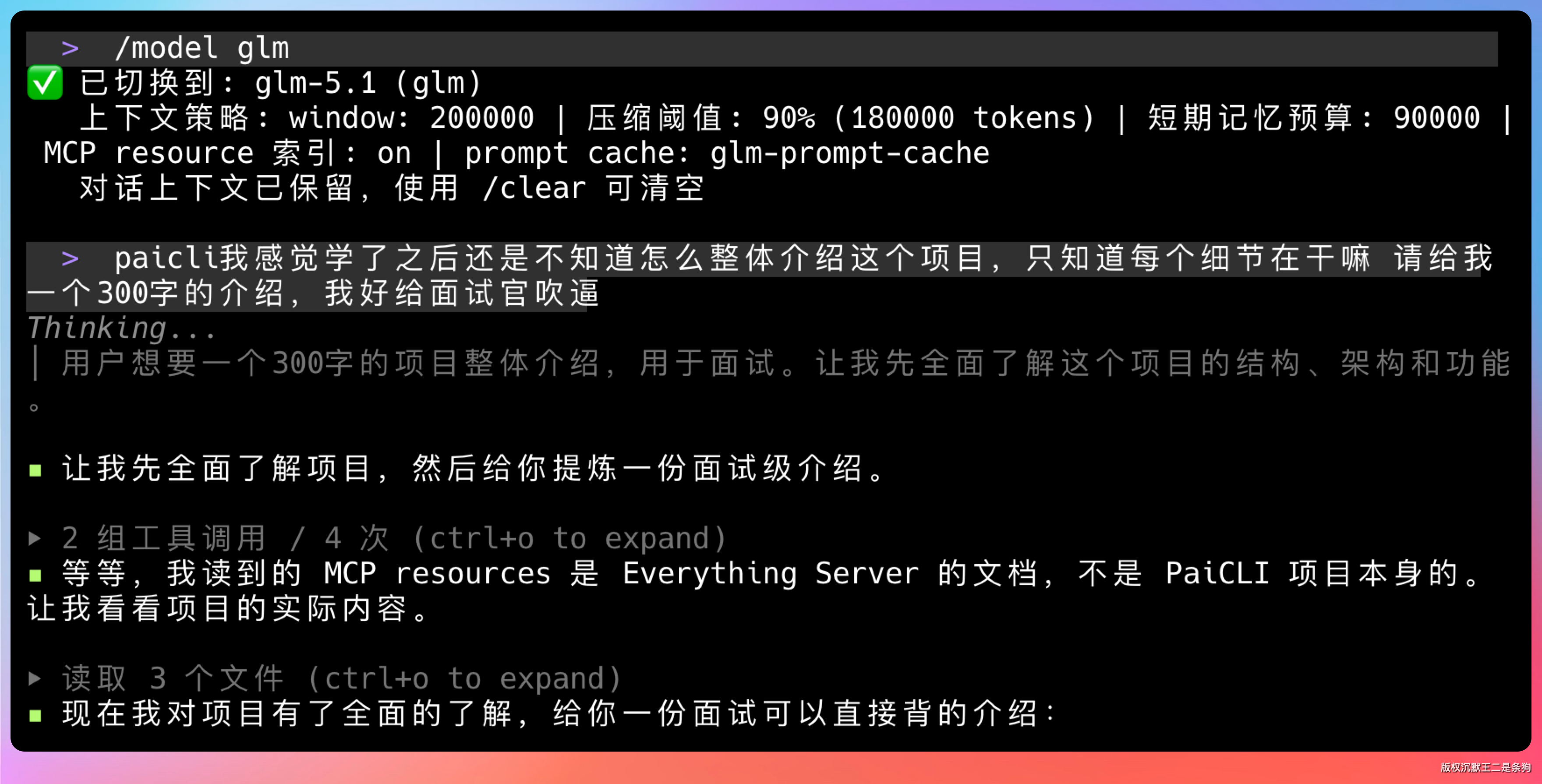
01、Agent CLI 的终端渲染有哪些方案
三种。
第一种是纯文本输出。
直接 print。好的地方是兼容性最强,任何终端都能正常显示。不好的地方也很明显,没有颜色、没有折叠、没有状态栏,信息密度低,用户体验差。
第二种是 Inline 流式输出,也是 PaiCLI 的默认方案。底部固定一个状态栏,显示当前模型、token 用量、上下文窗口占比、运行耗时。
最关键的是工具调用可以折叠。比如说 Agent 读了 3 个文件,终端只显示一行折叠摘要,按 Ctrl+O 展开可以查看具体内容。文件修改也有行内 diff 对比,改了什么一目了然。
第三种是全屏 TUI。独占整个终端窗口,可以做文件树、分栏布局、弹窗。用户体验最丰富,但需要全屏模式。PaiCLI 基于 Lanterna 库实现了这个方案,有对话区、状态栏和模态弹窗做审批确认。
最终我们选择了 Inline 作为默认的交互方式,因为它在信息密度和用户体验之间达到了一个不错的平衡。比较接近Claude Code和Qoder CLI的交互方式。
02、DECSTBM 是什么?状态栏怎么实现的
DECSTBM 全称是 DEC Set Top and Bottom Margins,是 VT100 终端定义的转义序列,用来设置终端的滚动区域。
可以通过一条 ESC[1;{n}r 指令,告诉终端只有第 1 行到第 n 行参与滚动,剩下的行保持不动。
PaiCLI 的做法是把终端底部留出 2 行不参与滚动。主内容在上方正常滚动输出,底部 2 行始终固定显示状态信息。
第一行是核心状态,包括 HITL 审批开关、MCP Server 连接数、Skill 加载数。
第二行是运行时数据,包括当前模型名称、运行阶段、上下文窗口使用率(用进度条可视化显示占比)、输入输出 token 数、缓存命中数、预估费用、运行耗时和当前工作目录。
注意,不是所有终端都支持 DECSTBM。
PaiCLI 在初始化时会检测终端能力,检查是否支持 ANSI、终端尺寸是否足够(至少 5 行 20 列),以及用户是否通过环境变量 PAICLI_NO_STATUSBAR 手动禁用了状态栏。
状态栏的更新频率怎么控制
状态栏的更新由调用方驱动,通常在每次收到 token 或者每个 Agent 迭代周期触发一次。
渲染器内部可以根据需要做节流处理,避免高频重绘带来的终端闪烁。
03、LSP 诊断注入是什么?对 Agent 有什么价值
“Agent 改了代码,编译出错了怎么办?”
PaiCLI 的 LSP 诊断注入就是解决这个问题的。
整个流程是这样的:Agent 执行文件写入操作后,系统的 edit hook 会自动触发。
诊断模块对修改过的文件会做语法分析,收集错误和警告信息,然后把诊断结果格式化成结构化文本,在下一轮 LLM 请求之前作为合成消息注入上下文。LLM 看到编译错误的具体位置和描述,就能在下一轮回复中自动修复。
当前的 MVP 版本对 Java 文件使用了 JavaParser 做轻量语法诊断。诊断结果的格式化也有讲究,每条诊断都包含错误等级、文件路径、行号、列号和具体信息,比如 [error] Foo.java:42:15 缺少分号 (javaparser)。LLM 拿到这种格式,能精确定位到具体的代码行,直接修复。

这样做的好处是,Agent 不用等用户手动编译就能发现编译错误并自动修复,实现了编辑、诊断、修复的自动循环。
04、Git Side-History 快照是怎么工作的
“Agent 把文件改坏了,怎么回滚?”
Agent 改文件是有风险的,所以快照和回滚机制是必须做的。
用户项目本来就有 git,Agent 每次改完文件 commit 一下不就行了?
不行,有三个原因。
- 第一,Agent 的自动快照会污染用户的 git log,用户的提交历史要有意义,不能是垃圾回收站。
- 第二,用户可能正在做 rebase 或者 merge,Agent 的 commit 会直接干扰 git 的状态机。
- 第三,快照不是有意义的 commit,混在正式分支里只会增加噪音。
PaiCLI 的解决方案是建一个完全独立的 side-git 仓库。
快照数据存储在 ~/.paicli/snapshots/ 目录下,按项目路径的哈希值组织目录结构,完全不碰用户的 .git 目录。底层用 JGit 完成所有操作,不依赖本机安装的 git 命令。
快照的时机分为三种。
- 第一种是推理前快照,在每轮 Agent 推理开始之前同步创建,确保基线状态已经保存。
- 第二种是推理后快照,在推理结束之后异步创建,记录本轮改动的最终状态。
- 第三种是恢复前快照,在用户执行恢复操作之前自动创建,防止恢复操作本身丢失当前状态。
推理前快照必须同步执行,因为 Agent 还没改文件之前的状态是回滚的基线。推理后快照可以异步执行,这样不会阻塞下一轮用户输入。
当用户执行 /restore <N> 命令,就能从第 N 个推理前快照恢复文件到工作区。恢复的过程是把快照中的文件内容写回工作区,用户的 .git 完全没影响。
快照的提交身份是什么
所有快照的提交者信息统一为 PaiCLI Snapshot <snapshot@paicli.local>,和用户的 git 身份完全隔离。
05、快照恢复会影响用户的 .git 吗
“恢复操作安全吗?会不会搞乱用户自己的 git 状态?”
不会。
Side-git 仓库和用户的 .git 是完全独立的两套系统。恢复操作只做一件事:把快照中的文件内容写回工作区。用户的 .git 目录、暂存区、分支信息全部不动。
恢复完之后,git status 会显示文件被修改了,这些修改和用户手动编辑文件的效果完全一样。用户可以选择 commit 保留这些改动,也可以 discard 放弃,主动权完全在用户手里。
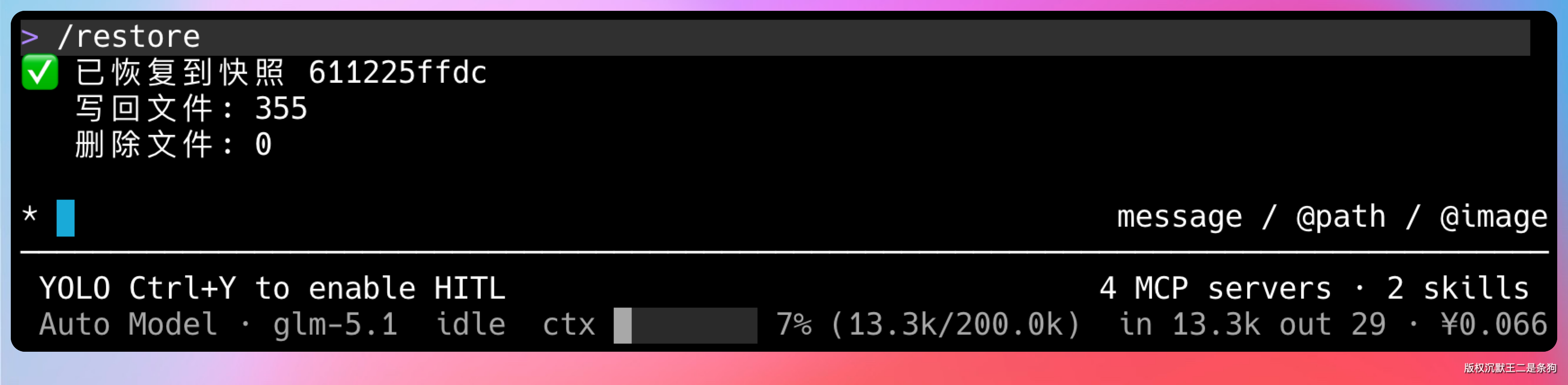
这里最关键的设计是恢复前快照。
用户恢复到某一轮推理之前的状态,万一恢复错了怎么办?
因为恢复操作之前自动拍了一个恢复前快照,所以可以再恢复回来。
恢复过程还会返回一个结果对象,告诉用户哪些文件被恢复了、哪些文件被删除了(因为这些文件在快照中不存在)。信息透明,用户清楚地知道恢复操作改动了什么。
06、异步后台任务是怎么设计的
“Agent 执行一个大任务,比如重构整个模块,用户需要一直等着吗?”
不需要。
PaiCLI 有一套后台任务系统,用户通过 /task add "增加一个hello 二哥" 提交任务后就可以做其他事情了。
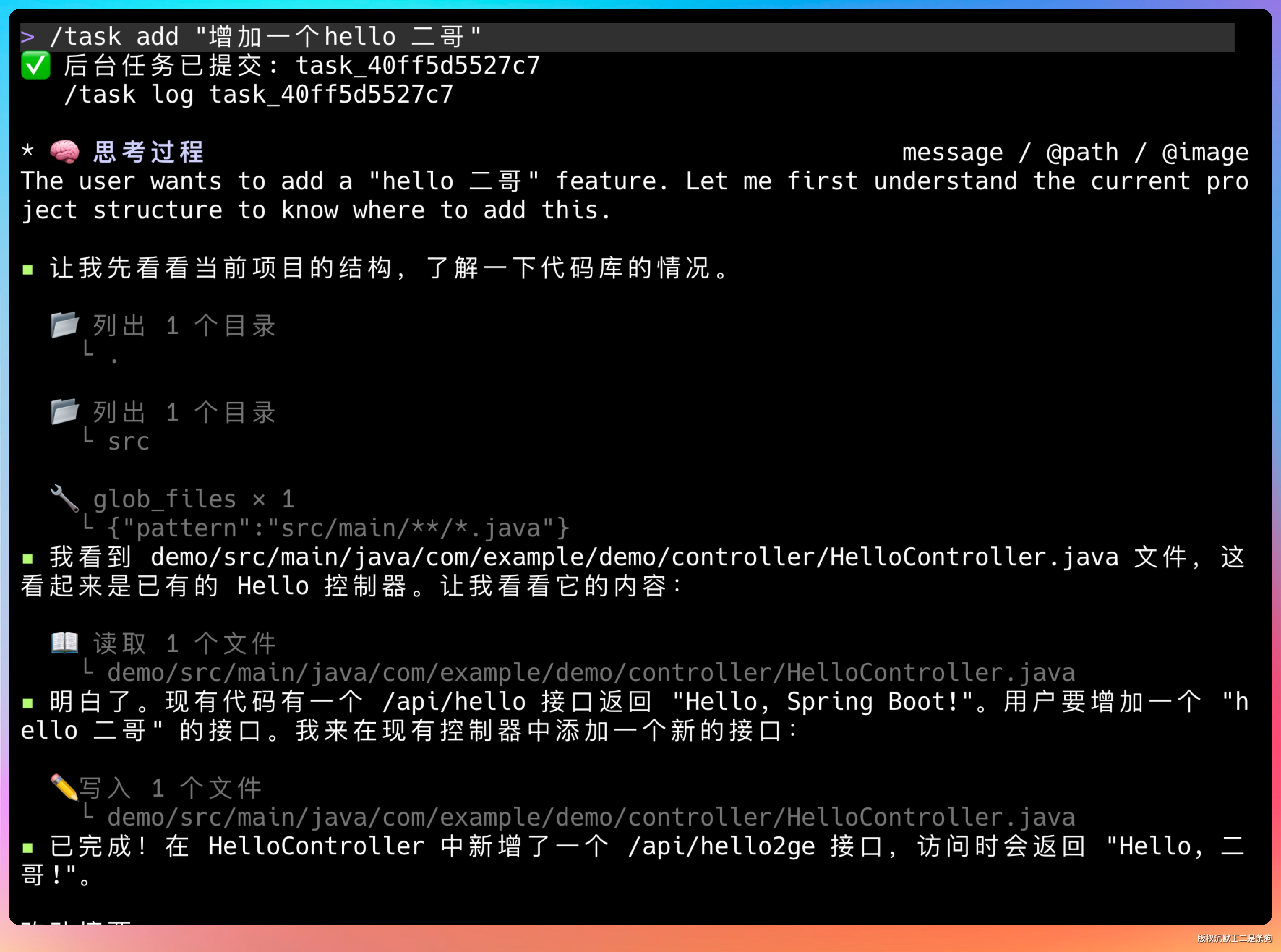
整体架构是这样的:
任务通过命令提交后进入 SQLite 排队,后台有一个 Worker Pool(默认 2 个 worker)不断从队列中领取任务执行。每个 worker 启动独立的 Agent 线程处理任务,完成后更新状态。
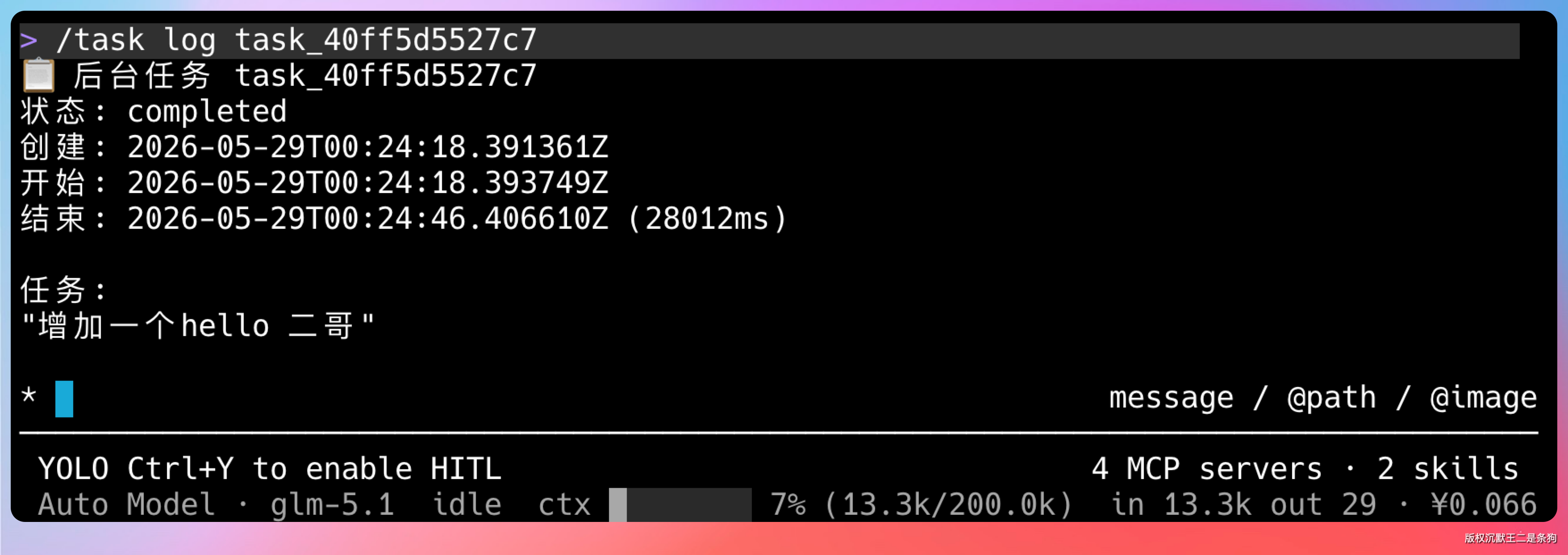
任务的生命周期是 enqueued → running → completed / failed / canceled。
Worker 领取任务时用了事务机制保证原子性。
先查询一条状态为 enqueued 的任务,然后用乐观锁(检查状态是否仍然是 enqueued)更新为 running。如果更新影响了 0 行,说明被其他 worker 抢先领走了,当前 worker 回滚后继续找下一个。防止了多个 worker 重复执行同一个任务。
任务执行失败了怎么处理
worker 捕获到异常后,把任务状态标记为 failed,错误信息写入数据库。
用户通过 /task log <id> 可以查看具体的执行摘要和错误详情。如果是线程中断(比如用户手动取消),状态标记为 canceled。无论哪种情况,worker 都会继续处理队列中的下一个任务,不会因为一个任务失败导致整个系统停摆。
07、PaiCLI 不就是个命令行工具吗?为什么还需要 HTTP API?
加了 HTTP API 之后,PaiCLI 就变成了一个可编程的 Agent 引擎。CI/CD 流水线可以调用 PaiCLI 做自动代码审查或测试生成,IDE 插件可以通过 HTTP 接口集成 Agent 能力,Web 面板可以用浏览器替代终端做交互。
核心有三个端点:
POST /v1/threads创建对话线程,POST /v1/threads/{id}/turns发起一轮交互,GET /v1/threads/{id}/events获取 SSE 流式事件。创建线程后提交一轮交互请求,请求异步执行,客户端通过 SSE 端点实时接收执行过程中的事件流。
第一步,先设置 API Key(必填)
export PAICLI_RUNTIME_API_KEY=test_key_12345第二步,启动 Runtime API 服务
java -jar target/paicli-1.0-SNAPSHOT.jar serve --http --port 8080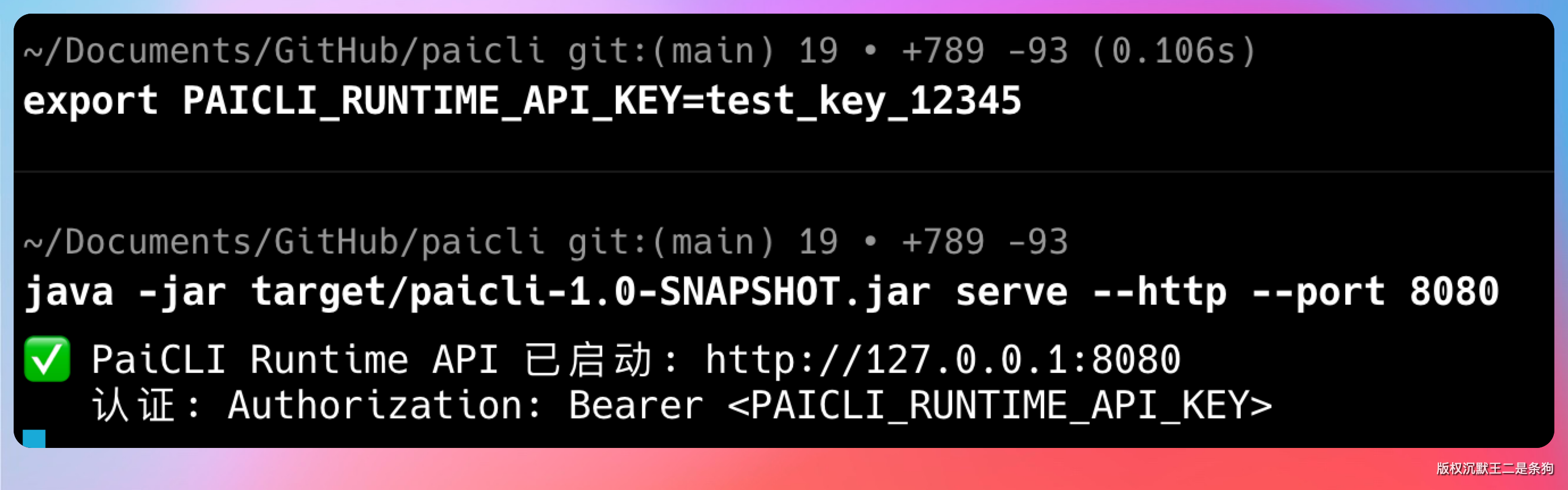
第三步,创建对话线程。
curl -X POST http://127.0.0.1:8080/v1/threads \
-H "Authorization: Bearer test_key_12345" \
-H "Content-Type: application/json"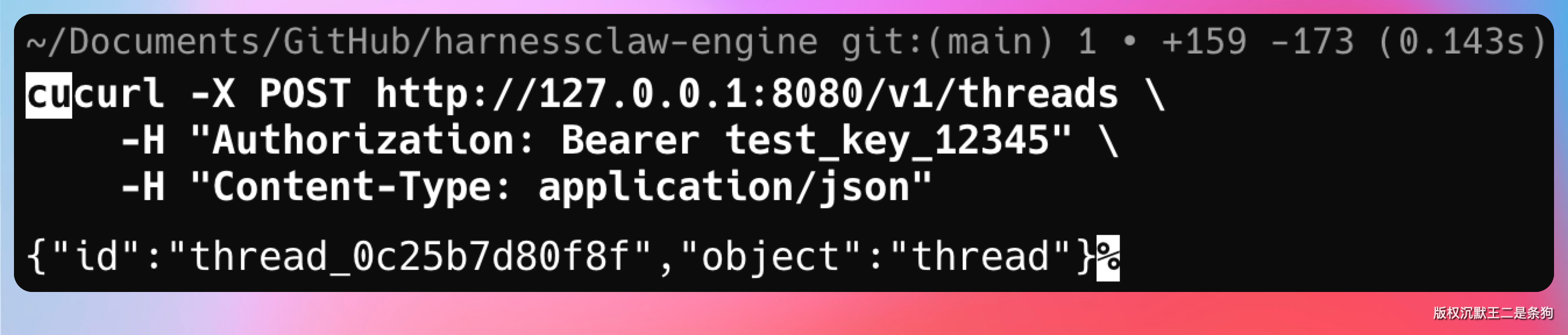
第四步,提交一轮交互。
curl -X POST http://127.0.0.1:8080/v1/threads/<thread_id>/turns \
-H "Authorization: Bearer test_key_12345" \
-H "Content-Type: application/json" \
-d '{"input":"hello world"}'注意替换 <thread_id> 为上一步创建线程返回的 ID。
curl -X POST http://127.0.0.1:8080/v1/threads/thread_0c25b7d80f8f/turns \
-H "Authorization: Bearer test_key_12345" \
-H "Content-Type: application/json" \
-d '{"input":"hello world"}'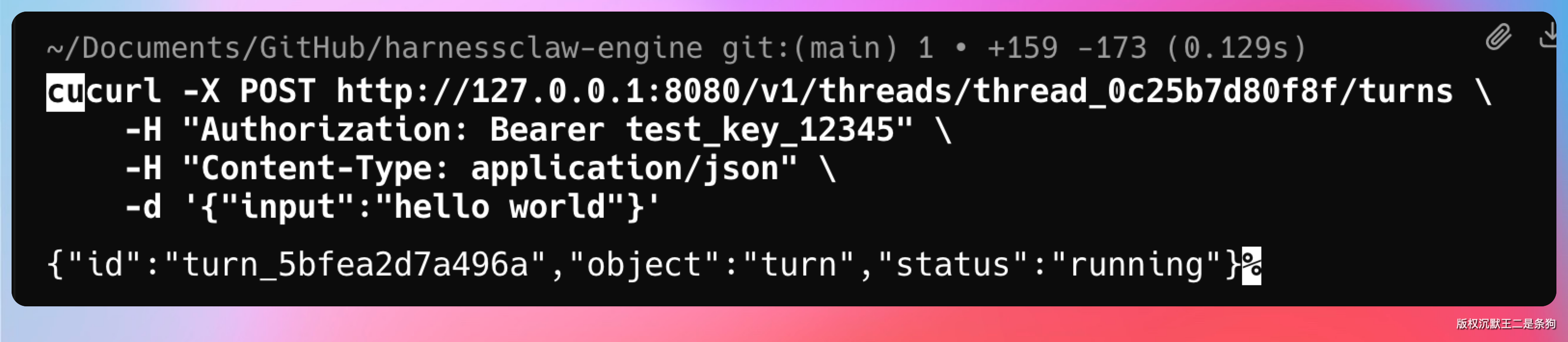
第五步,订阅事件流。
curl http://127.0.0.1:8080/v1/threads/<thread_id>/events \
-H "Authorization: Bearer test_key_12345"
curl http://127.0.0.1:8080/v1/threads/thread_0c25b7d80f8f/events \
-H "Authorization: Bearer test_key_12345"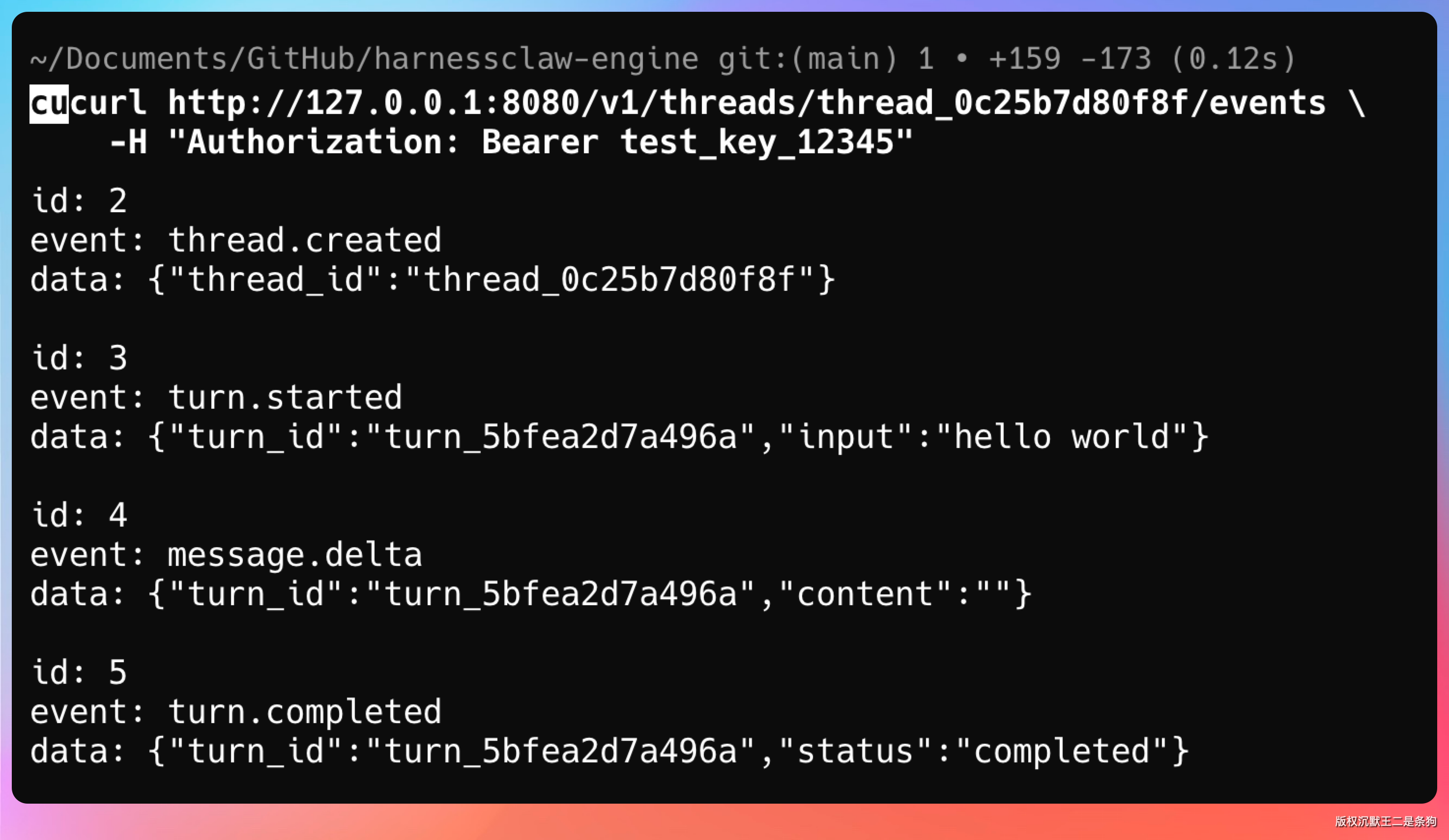
安全设计有三层保护。
第一层,只监听 127.0.0.1,不接受外部连接,从网络层面隔离了攻击面。
第二层,必须配置 API Key,每次请求都要在 Authorization 头或 X-PaiCLI-API-Key 头中带上密钥,校验不通过直接返回 401。
第三层,基于 JDK 内置的 HttpServer 实现,不引入 Netty、不引入 Spring Web,零额外依赖,减少了潜在的安全漏洞面。
线程和事件数据也做了持久化,存储在 ~/.paicli/runtime/runtime.db 的 SQLite 数据库中。
事件表按 thread_id 和自增 id 建了联合索引,SSE 端点支持 ?after=<lastId> 参数做增量拉取,客户端断线重连后不会丢失事件。
08、Agent 只能处理文本吗?图片能传进来吗?
可以。
用户贴一张截图,PaiCLI可以识别出图片内容。
这是原图。
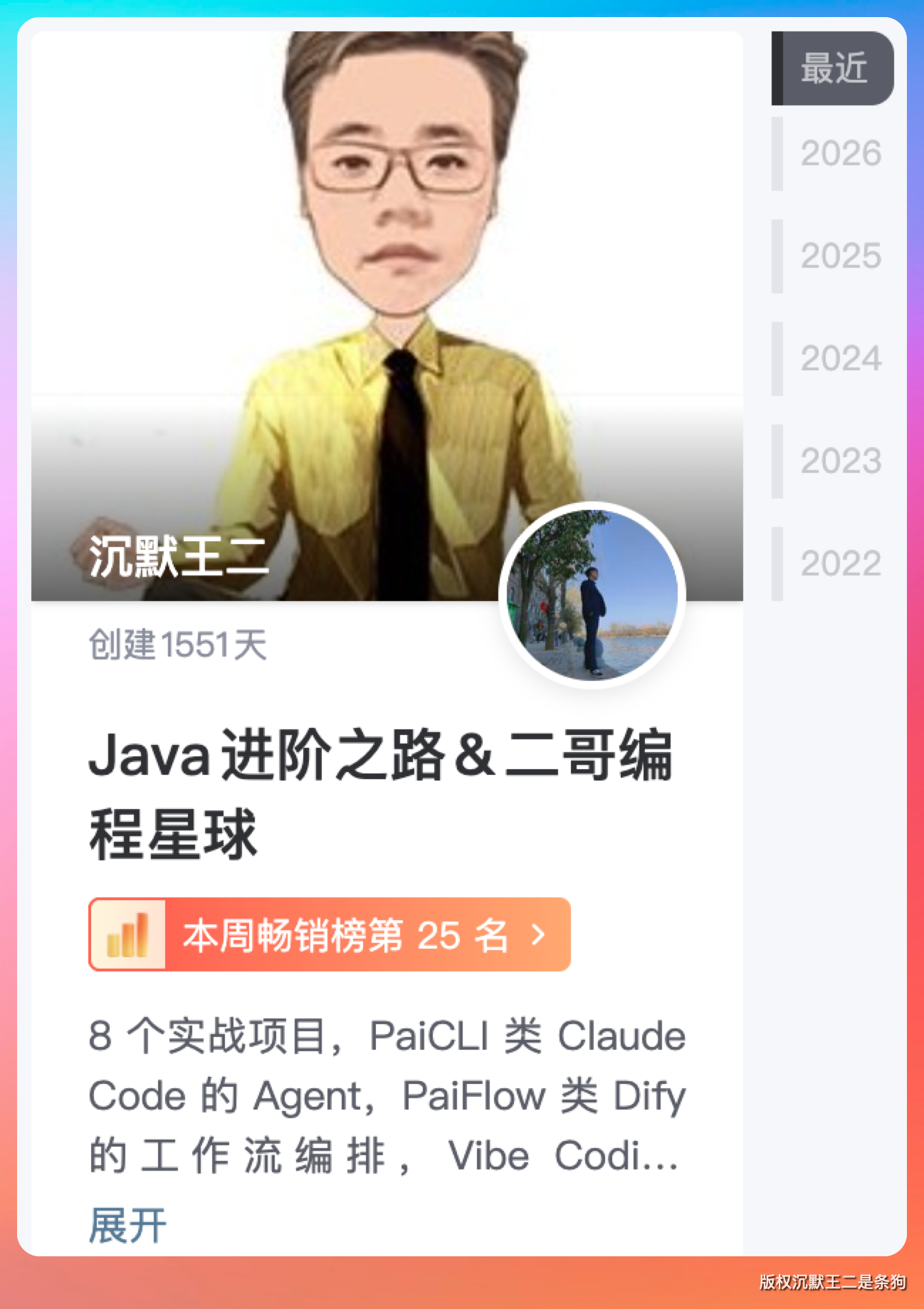
PaiCLI 是怎么实现的?
首先是协议适配。
OpenAI 兼容协议的 content 字段需要从纯文本字符串扩展为内容块列表,包含 text 和 image_base64 两种类型。纯文本时保持 string 格式不变(兼容旧接口),有图片时切换为数组格式。
其次是图片压缩。
图片按 tile 数计算 token,一张截图可能消耗几千 token。PaiCLI 的处理策略分几步:
先检查文件大小是否超过 50MB 的输入上限,然后判断 base64 编码后是否超过 5MB 的 API 限制。如果不超限且没有透明通道,直接使用原始数据。如果有透明通道,先把背景统一填充为白色再编码,因为不同模型对 alpha 通道的处理不一致。如果超过大小限制,先按比例缩放到 2000x2000 以内,然后尝试 PNG 无损编码。如果 PNG 仍然超限,就逐级降低 JPEG 质量(从 0.85 到 0.25 共五档),直到文件大小满足要求。
如果图片缩放了,坐标映射怎么处理
压缩后的元信息里会标注原始尺寸和显示尺寸的比例关系,比如“坐标乘以 2.00 可映射回原始图片”。如果 Agent 需要对图片中的特定位置做标注或定位,可以根据这个比例换算回原始坐标。
09、Renderer 接口抽象的设计思路是什么
“有几种渲染方案,Agent 核心逻辑怎么和渲染解耦的?”
经典的策略模式。
PaiCLI 定义了一个统一的 Renderer 接口,所有渲染相关的操作都会到这个接口上。
比如
appendToolCalls表示“有一组工具调用需要展示”,至于怎么展示,折叠块、全屏分栏还是纯文本,由具体实现决定。appendDiff表示“有一个文件修改需要对比展示”,updateStatus表示“运行状态有更新”,promptApproval表示“需要用户确认一个操作”。
每个方法对应一个交互意图,而不是一个视觉组件。
三个实现各自怎么做?
Inline 模式用 ANSI 颜色和折叠块渲染工具调用,用行内 diff 渲染文件对比,用底部状态栏显示状态,用终端提示做审批。
全屏 TUI 把工具调用输出到对话区面板,diff 用系统消息展示,审批用模态弹窗(通过 CountDownLatch 做跨线程同步)。
纯文本模式就是 println,按工具名分组展示调用摘要,审批用命令行输入循环。
10、LSP 诊断注入和 IDE 的红色波浪线有什么区别
“你说的 LSP 诊断注入,和 IDE 里的红色波浪线不是一回事吗?”
本质是一样的,都是对代码做语法分析后输出诊断信息。但消费者不同。
IDE 的红色波浪线,消费者是人。人看到波浪线,用眼睛定位出错位置,通过阅读悬浮提示理解错误原因,然后手动修改代码。
Agent 的 LSP 诊断注入,消费者是 LLM。诊断结果被格式化成结构化文本,注入到下一轮请求的上下文中。LLM 收到后在推理过程中自动定位并修复错误。触发时机是 post-edit hook,只有文件被写入后才触发一次。展示方式是纯文本,带有行号、列号和错误等级。
每条诊断的格式是 [error] Foo.java:42:15 缺少分号 (javaparser),行号、列号、错误等级、来源一目了然。
同时还有彩色版本用于终端显示,error 红色、warning 黄色、info 灰色,方便用户在终端里也能直观看到诊断结果。
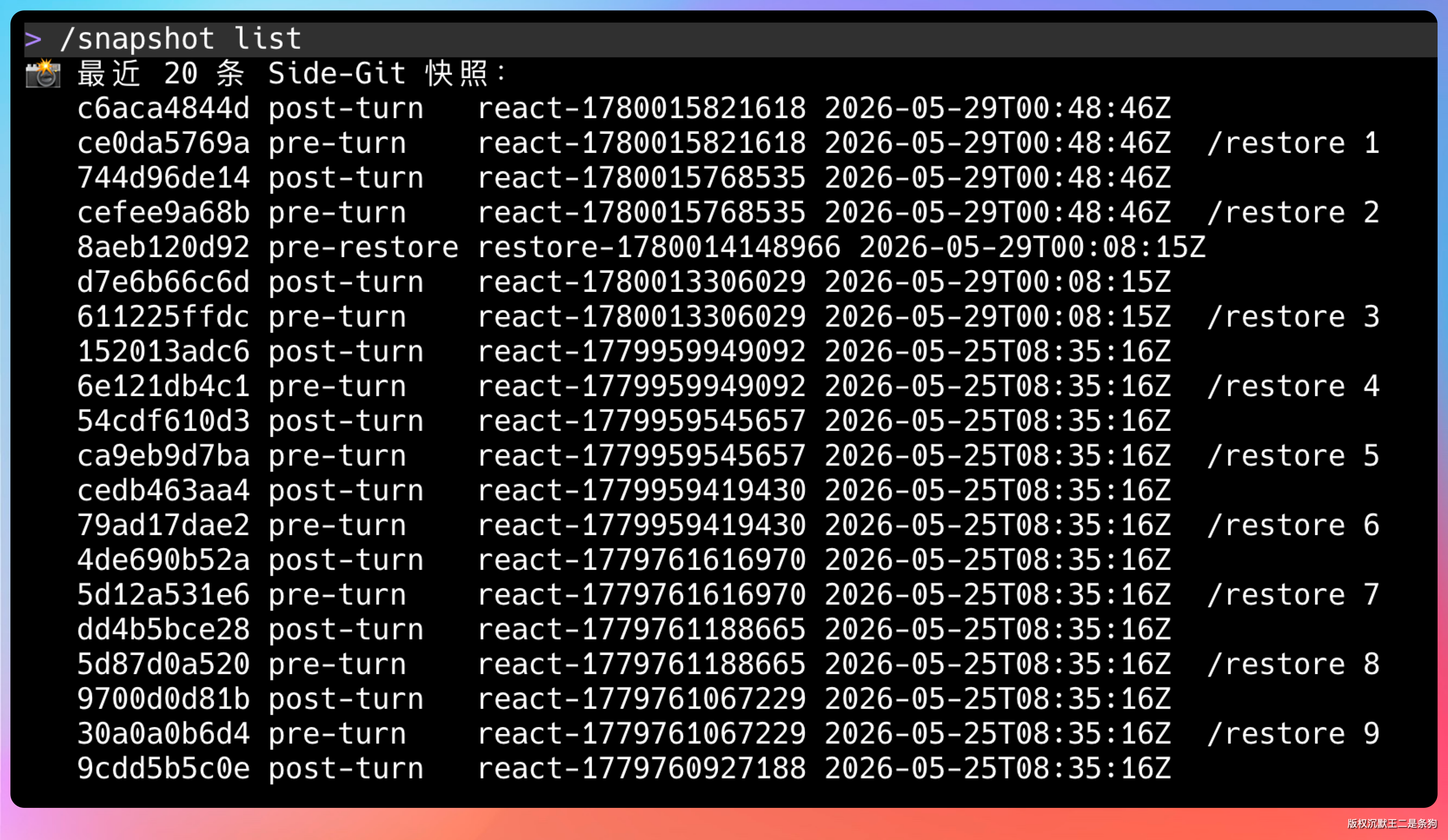
11、Side-Git 快照的性能影响大吗?怎么优化
“快照需要遍历所有文件、计算哈希,对大项目性能开销怎么样?”
我们通过四个策略把影响控制在了可接受范围内。
第一个是排除大文件目录。默认排除 .git、node_modules、target、dist、.idea、*.class、*.jar,以及 PaiCLI 自身的快照目录。用户可以通过配置项追加自定义排除规则。排除匹配支持精确匹配、目录前缀匹配和 glob 模式三种方式。
第二个是区分同步和异步。推理前快照必须同步执行,因为 Agent 改文件之前的基线必须确保已经保存。推理后快照异步执行,不阻塞下一轮用户输入。
第三个是快照数量上限。默认保留最近 50 轮的快照,超出的自动清理。也提供了手动清理命令。
第四个是用 JGit 纯 Java 实现,不 fork git 子进程。避免了进程创建和销毁的开销,对象写入在 Java 堆内完成。
12、Runtime API 为什么选 SSE 而不是 WebSocket
“你们的 API 用了 SSE,为什么不用 WebSocket?”
这是一个经典的技术选型题。
先看场景需求:用户提交一轮输入后,等 Agent 流式返回结果。这是一个典型的单向流式场景,服务端持续推送,客户端只需要接收。
SSE 在这个场景下有三个优势。
第一,它就是普通的 HTTP 长连接,所有 HTTP 客户端和代理都能支持,不需要担心企业内网防火墙拦截。WebSocket 使用独立的 ws:// 协议,部分代理和防火墙对它的支持不稳定。
第二,SSE 的实现复杂度低很多,服务端只需要往 HTTP 响应里持续写 data: 格式的文本行即可。WebSocket 需要处理握手升级、帧编解码、心跳维护等额外逻辑。
第三,和 OpenAI 的流式 API 保持一致。OpenAI 的 streaming response 也是 SSE,用户已有的客户端库可以直接复用。
PaiCLI 的 SSE 实现也做了细节处理。
每个事件带有自增 id,客户端断线重连时通过 ?after=<lastId> 参数做增量拉取,不会丢失断线期间的事件。
事件类型区分了 thread.created、turn.started、message.delta、turn.completed 四种,客户端可以精确控制对不同类型事件的处理逻辑。
13、从产品角度看,Agent CLI 的“好用”体现在哪些方面
“最后一个开放题。你觉得一个好用的 Agent CLI 应该具备哪些特质?”
可预测性。用户能预期 Agent 下一步会做什么。PaiCLI 的 Plan-and-Execute 模式在执行前先展示计划,HITL 审批让用户对危险操作有确认权。Agent 不是黑箱,它要改什么文件、执行什么命令,用户得清楚。
可恢复性。Agent 搞砸了能回滚。Git Side-History 快照就是这个目的,一条 /restore <N> 命令就能回到改动之前的状态。
可观测性。用户能看到 Agent 在做什么。Token 用量在状态栏实时更新,上下文窗口使用率用进度条可视化显示,工具调用有折叠日志,操作审计记录到 JSONL 文件。这些信息让用户对 Agent 的运行状态有清晰的感知。
渐进式。新用户用 ReAct 模式就能完成基本任务,进阶用户按需解锁 Plan 模式、Team 协作、Skill 机制、MCP 扩展。PaiCLI 的 slash 命令面板(输入 / 触发)也是这个思路,常用的放在前面。
容错性。网络断了、MCP Server 挂了、LLM 超时了,每种故障都有优雅的降级路径,不会直接崩溃退出。
PaiCLI如何写到简历上?
项目名称:PaiCLI -- AI Agent 命令行工具
项目简介:基于 Java 17 的 AI Agent CLI 产品,对标 Claude Code,从 ReAct 循环演进到完整 Agent 产品形态,覆盖 TUI 终端渲染、LSP 诊断注入、Git 快照回滚、异步任务、Runtime API 和多模态输入。
技术栈:Java 17、JLine(终端交互)、Lanterna(全屏 TUI)、JGit(Git 操作)、JavaParser(语法诊断)、SQLite(任务持久化)、JDK HttpServer(Runtime API)、ANSI/VT100 转义序列
核心职责:
- 抽象 Renderer 接口,统一 Inline 流式、Lanterna 全屏、Plain 纯文本三种终端渲染形态,Agent 核心逻辑与渲染完全解耦。Inline 模式基于 DECSTBM 实现底部常驻状态栏,工具调用支持折叠/展开和行内 diff 对比。
- 实现 LSP 诊断注入机制,Agent 每次写文件后自动触发 JavaParser 语法诊断,诊断结果格式化为结构化文本注入下一轮 LLM 请求,构建编辑-诊断-修复自动循环。
- 设计 Git Side-History 快照系统,基于 JGit 维护独立 side-git 仓库,每轮推理前后自动快照,不污染用户 .git 历史。支持一键回滚。
- 实现 Runtime API 和异步后台任务系统,基于 JDK HttpServer + SSE 提供 RESTful 接口,支持 CI/CD 和 IDE 插件集成。任务状态持久化到 SQLite,进程重启自动恢复,保证 at-least-once 执行语义。