AI Agent 面试题第五弹:Prompt 分层架构、Skill 系统、提示词工程 13 题
AI Agent 面试题系列第五弹,这次聊的是Prompt 与 Skill。
Prompt 是 Agent 的灵魂。
写得好,Agent 知道什么时候该用什么工具、碰到异常该怎么处理;写得差,Agent 干啥啥不行。
而 Skill 是把 prompt 工程化的手段——从“一坨几千字的 system prompt”变成“按场景按需加载的专家手册”,既能降低 token 的消耗,又能提升 Agent 的行为质量。
01、Agent 的 system prompt 一般包含哪些内容?
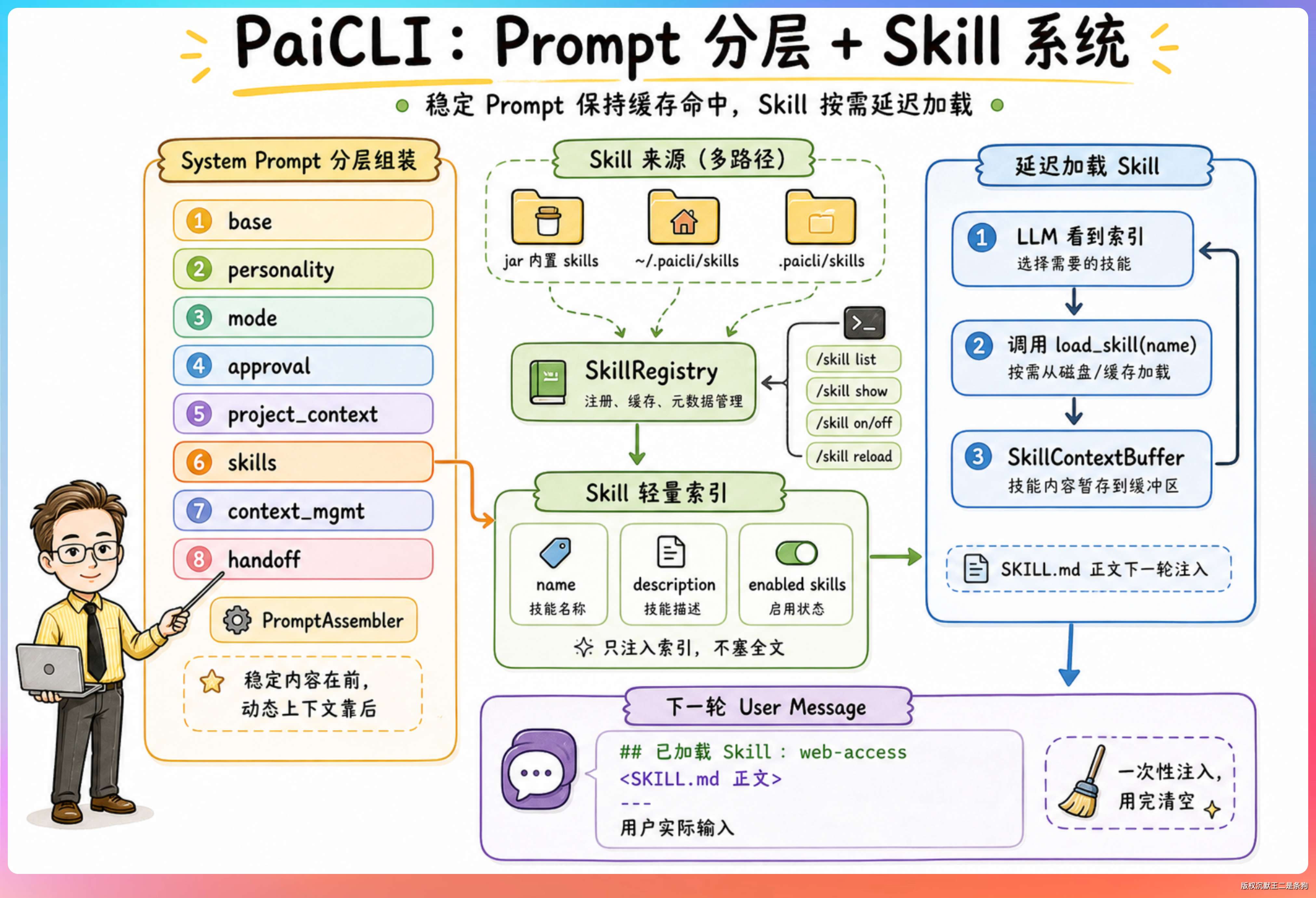
PaiCLI 的 system prompt 可以概括为四个核心模块。
首先是角色定义,告诉 LLM 你是谁、能做什么。PaiCLI 的 base.md 第一段就写了:你是 PaiCLI,一个面向代码库工作的智能编程 Agent。
然后是行为规范,负责输出格式、语调等。比如 base.md 里有个 ## Language 模块,明确写了“请用中文回复用户”,代码和 API 名称才保留原文。组装的时候会要求这个模块必须存在。
第三块是工具使用指导。不能只写“合理使用工具”这类泛化要求,而要具体到场景——读文件用 read_file,不要用 execute_command cat。
第四块是安全约束,明确哪些操作不能做、哪些操作需要用户确认。
02、Prompt 分层架构是怎么设计的?
PaiCLI 早期的 system prompt 是硬编码在 Java 代码里的,改一句话要重新编译。后来做了分层改造,把 system prompt 拆分成独立的 Markdown 文件,按职责分目录存放。
先看目录结构:
src/main/resources/prompts/
├── base.md # 核心规则(工具使用、输出格式)
├── personalities/calm.md # 语调(冷静专业风格)
├── modes/
│ ├── agent.md # ReAct 模式指令
│ ├── plan.md # Plan task executor 指令
│ ├── planner.md # Planner 规划器指令
│ ├── team-planner.md # Multi-Agent Planner
│ ├── team-worker.md # Multi-Agent Worker
│ └── team-reviewer.md # Multi-Agent Reviewer
├── approvals/
│ ├── suggest.md # HITL 建议审批
│ ├── auto.md # 自动放行
│ └── never.md # 永不放行
└── context/
└── context-management.md # 上下文管理策略PaiCLI 启动时会把这些 Markdown 文件按固定顺序拼装成最终的 system prompt。
组装顺序是固定的:先拼核心规则,再拼语调风格,然后是当前模式的指令,接着是审批策略、项目上下文、Skill、上下文,最后是本轮对话的交接信息。
03、为什么提示词的组装顺序是“不变的在前、动态的在后”?
LLM 推理时,每个 token 会计算出一对 Key-Value(KV),缓存起来。如果连续两次请求的 prompt 前缀完全相同,服务端可以复用上次的 KV Cache,跳过重复计算。前缀越稳定,cache 命中率越高,推理越快、成本越低。
PaiCLI 的排列策略
PaiCLI 的组装顺序严格遵循**“不变内容放前,动态内容放后”**的原则。
这样排列后,越靠前的稳定内容越容易持续命中 cache,动态变化的内容集中在后段,服务端只需要重点处理新增或变化的上下文。反过来,如果把 Skill、项目上下文这类动态内容放到前面,即使 base.md 没有变化,也可能破坏前缀一致性,导致缓存收益下降,推理延迟和 token 成本都会受到影响。
04、用户怎么覆盖内置 prompt?
PaiCLI 支持三层覆盖,优先级从低到高:
- jar 内置(最低优先级):
src/main/resources/prompts/ - 用户级:
~/.paicli/prompts/ - 项目级(最高优先级):
<project>/.paicli/prompts/
加载逻辑是链式的:先加载 jar 内置的,然后依次检查用户级和项目级目录里有没有同名文件,有的话直接替换。
覆盖粒度是整文件替换,不支持部分修改。好处是简单直观,用户完全控制内容;代价是如果只想在 agent.md 末尾加一段话,也得把整个文件复制出来再改。
安全性考虑
既然项目级可以覆盖内置 prompt,就存在通过恶意项目配置注入提示词的风险。
PaiCLI 在路径加载时做了两层校验:一是文件路径不能以 / 开头、不能包含 ..,防止路径穿越;二是解析后的路径必须落在对应根目录之内,超出范围的直接拒绝。
05、什么是 Skill?它和 Tool 有什么区别?
Tool 是一个可执行的函数,输入参数,返回结果。比如 read_file、execute_command、web_fetch。
Skill 的核心是一份按场景组织的知识和决策指引,主体通常是 SKILL.md。它也可以携带 references/、scripts/ 等辅助资源,但它本身不等同于 Tool,主要作用是指导 Agent 如何选择和使用工具。
| 维度 | Tool | Skill |
|---|---|---|
| 形式 | 代码函数 | SKILL.md + 辅助资源 |
| 触发 | LLM 通过 tool_calls 调用 | LLM 通过 load_skill 工具加载 |
| 内容 | 执行逻辑 | 决策手册 + 最佳实践 + 经验数据 |
| 注入位置 | tools 字段 | user message 前置 |
每个 Skill 包含 name、description、body(SKILL.md 正文,真正注入给 LLM 的内容)和 references 目录(参考资料),来源分三种:BUILTIN(内置)、USER(用户级)、PROJECT(项目级)。
举个具体例子:web_fetch 是 Tool(抓取网页的函数),web-access 是 Skill(告诉 Agent 什么时候用 web_fetch、什么时候用浏览器 MCP、各个站点的反爬经验)。
当工具数量增多以后,仅靠 system prompt 堆积规则已经不够用了。Skill 的做法是按场景把决策指引打包,LLM 需要的时候再按需加载。
这里可能会有一个追问:为什么不把 Skill 的内容直接写进 Tool 的 description 里?
Tool description 是随 tools 字段一起下发的,每一轮对话都会携带全量 Tool 列表。
如果把决策指引塞进 description,20 个工具的 description 会占掉大量 token,而且用户这轮根本用不到的工具也会被注入。
Skill 的延迟加载机制可以做到按需注入,只有 LLM 判断需要的时候才加载对应的决策手册,token 利用率高得多。
06、Skill 的延迟加载机制了解吗?
Agent 启动时,只把所有启用 Skill 的 name + description 渲染成一段索引,注入到 system prompt 末尾,整个索引控制在 4KB 以内。LLM 看到的相当于一份菜单,而不是所有 Skill 的完整内容。
运行时,LLM 根据用户输入判断需要哪个 Skill,主动调用 load_skill(name) 工具。加载后 Skill 的正文会写入一个缓冲区,在下一轮对话时前置注入到 user message 前面。注入是一次性的,取出后自动清空,不会跨轮重复注入。
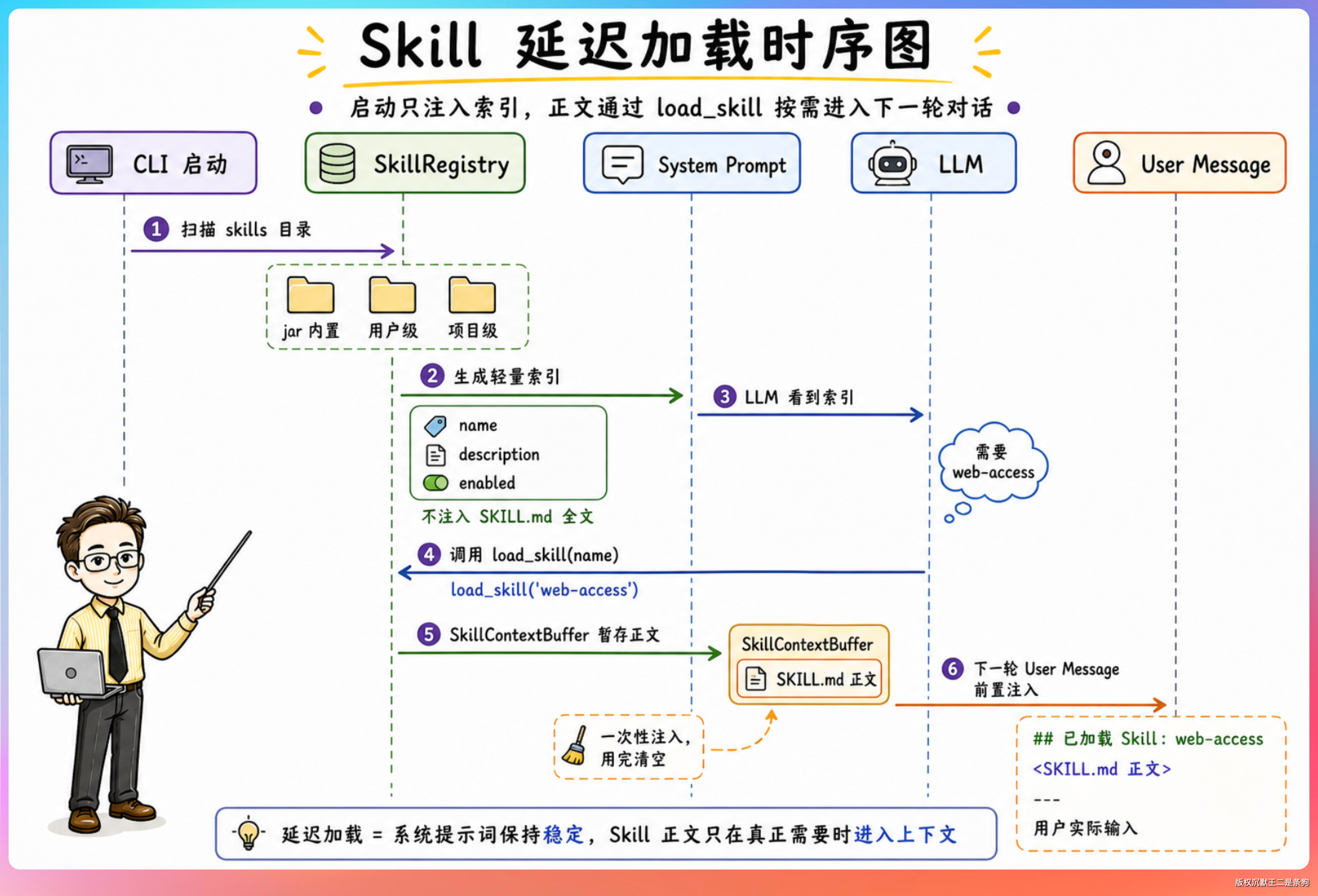
为什么不把所有 Skill 塞进 system prompt
假设有 20 个 Skill,每个完整手册 2000-3000 token,全部注入就是 40k-60k token。绝大部分场景下用户只需要 1-2 个 Skill,其余内容会造成不必要的上下文开销。
所以 PaiCLI 的 Skill 加载是 延迟加载的。
加载失败怎么处理
LLM 调用 load_skill(name) 时,可能遇到两种异常情况。
如果 Skill 名称不存在,系统会返回“Skill 未找到,可用 /skill list 查看可用 Skill”的提示信息,而不是抛异常。
如果 Skill 存在但被用户禁用了,会返回“Skill 已被禁用,可用 /skill on 启用”的提示。
两种情况都是把错误信息作为工具返回值交给 LLM,由 LLM 决定下一步怎么做——可以换一个 Skill,也可以直接用通用知识回答。不会因为某个 Skill 加载失败就中断整个对话流程。
07、Skill 缓冲区的容量控制怎么做的?
Skill 加载会占用 token,如果不做容量控制,buffer 会随着工具调用持续膨胀。
PaiCLI 的做法是最多保留 3 个 Skill,超出后按加载顺序淘汰最早进入缓冲区的那个。底层用 LinkedHashMap 的插入顺序实现,不需要额外的数据结构。如果同名 Skill 被重复加载,会先删除旧记录再插入新记录,既避免重复,也刷新加载顺序。
为什么用 LRU 而不是 LFU(按频率淘汰)?
因为 Skill 的使用场景是单次会话内的任务切换,不是长期高频访问。LRU 的语义更贴合实际——最近加载的 Skill 和当前任务的相关性最高,最早加载的大概率已经用完了。LFU 还需要额外维护频率计数器,复杂度更高但收益不大。
还有一个细节是缓冲区的读取是一次性的,取出后自动清空,上一轮注入过的 Skill 不会下一轮再注入一次。
因为异步工具调用可能在不同线程触发 load_skill,缓冲区做了 synchronized 线程安全处理。Multi-Agent 模式下,Planner、Worker、Reviewer 各持一个独立的缓冲区实例,避免角色间的提示词污染。
08、web-access Skill 具体包含什么内容?
web-access 是 PaiCLI 的首个内置 Skill,也是最能体现 Skill 设计理念的例子。
它的目录结构包含一个 SKILL.md 主文件和一组 references 子目录(按站点分类的经验文档,覆盖 GitHub、掘金、微信公众号、X、小红书、知乎专栏等)。
SKILL.md 的核心内容分四块。

第一块先判断是否需要联网,再选择工具,然后执行,最后验证结果。不是直接联网,而是先判断本地知识能否解决。
第二块是工具选择表,给出 web_fetch 和浏览器 MCP 的决策矩阵,静态页面用 web_fetch,动态渲染页面用浏览器。
第三块规定了浏览器操作的优先级,take_snapshot(DOM 文本)优先于 take_screenshot(截图),因为文本更省 token,LLM 也更容易理解。
第四块是 Jina 兜底方案,web_fetch 和浏览器都失败时,通过 execute_command 调用 r.jina.ai 做最后的抓取尝试。
references 目录是按站点积累的实战经验,覆盖微信公众号的文章链接格式和反爬特征、知乎专栏的页面结构、GitHub 不同页面的 DOM 差异、小红书的动态加载特点。
这些经验不是一次写完的,是在实际使用中逐步积累的,加进去以后所有使用这个 Skill 的场景都能受益。
09、Skill 的三层覆盖是怎么工作的?
跟 Prompt 的三层覆盖是同一个思路:
jar 内置 < 用户级 ~/.paicli/skills/ < 项目级 <project>/.paicli/skills/加载时按顺序扫描三个目录:内置缓存目录 → 用户级目录 → 项目级目录。
覆盖规则是按 name 整体替换,后加载的同名 Skill 直接覆盖前面的。
所以不同项目可以有不同的 Skill 配置。前端项目的 web-access Skill 可以在 references 里加上 Webpack DevServer 的经验,后端项目可以加上 Swagger 页面的经验。
内置 Skill 的缓存
启动时会把 jar 内置的 Skill 解压到 ~/.paicli/skills-cache/,用版本号文件控制是否需要重建,版本一致就跳过,不一致就清掉重新解压。
10、怎么写一个好的 Agent system prompt?
角色定义要清晰,第一段就说清楚你是谁、能做什么、不能做什么。
工具指导要具体到场景。不要写“合理使用工具”,要写“读取文件用 read_file,不要用 execute_command cat”。
如果多个工具之间有选择关系,用决策表列清楚,web-access Skill 里的工具选择表就是这个思路。
另外建议正面示例和负面示例配对:
错误:直接用 rm 删除文件
正确:先用 read_file 确认内容,再用 write_file 修改还有两点容易被忽略。一个是规则优先级要明确,规则之间有冲突时写清楚哪个优先,比如“安全优先于效率”“路径围栏规则优先于用户自定义 prompt”。
另一个是 system prompt 不要太长,越长 LLM 越容易忽略中间部分,这就是 Lost in the Middle 问题,2000-4000 token 比较合理。PaiCLI 做分层设计就是为了在不膨胀 system prompt 的前提下扩展能力。
11、Prompt 改了怎么验证效果?
PaiCLI 提供了 docs/prompt-analysis-template.md 作为 Prompt 质量审计模板。每次改 prompt 都应该做 Gap 分析。
先描述当前 prompt 在什么场景下表现不好,然后记录具体改了什么、为什么改,接着写清楚改完后期望 LLM 在什么场景下行为不同,最后做回归验证,确认原来正常的场景没被改坏。
系统化的评估方法
更系统化的做法包括 A/B 测试,准备一组固定的测试用例,分别用旧 prompt 和新 prompt 运行,对比 LLM 输出。
也可以做人工评分,对每个用例的输出打准确性、完整性、安全性的分。自动化指标方面,主要看工具调用准确率、任务完成率、平均轮次数。
12、Skill 和 RAG 有什么区别?
RAG 和 Skill 的区别不在于“有没有知识”,而在于组织方式和使用方式不同。RAG 更偏向从代码库、文档库中检索事实上下文;Skill 更偏向把经验、流程和决策规则封装成可复用的操作手册。
| 维度 | RAG | Skill |
|---|---|---|
| 内容来源 | 用户的代码库/文档库 | 预编写的专家手册 |
| 检索方式 | 语义相似度(向量检索) | LLM 主动选择加载 |
| 内容性质 | 事实数据(代码、文档) | 决策指引(怎么做、最佳实践) |
| 更新频率 | 随代码变化自动更新 | 随经验积累手动更新 |
| 注入时机 | 每轮自动检索 | LLM 判断需要时按需加载 |
举个例子,用户说“帮我看看这个 Spring Boot 项目的配置问题”。RAG 检索出项目里的 application.yml、pom.xml 等配置文件内容,这些是当前项目的事实上下文。
Skill 加载一份 Spring Boot 相关的决策手册,告诉 Agent 配置优先级如何判断、常见陷阱有哪些、排查顺序应该怎么组织,这些是可迁移的方法论。
13、如果让你设计一个 Skill 体系,你会怎么做?
这道题前面的问题其实已经把各个模块讲过了,这里从整体架构的角度做一个串联,重点放在几个容易被忽略的设计决策上。
结构标准化。每个 Skill 是一个目录,包含 SKILL.md(决策手册)、references/(参考资料)和可选的 scripts/(辅助脚本)。结构统一以后,新 Skill 的编写成本低,加载逻辑也不需要改动。
延迟加载 + LLM 主动触发。启动时只注入索引,运行时按需加载,前面 06 题已经讲过。这里补充一个决策:触发方式由 LLM 根据 description 自行判断,而不是做关键词硬匹配。原因是 LLM 的语义理解能力比正则匹配强得多,硬编码触发词反而容易遗漏相关场景。
三层覆盖 + 经验积累。内置 < 用户级 < 项目级,references 目录按场景持续积累经验数据。
容量控制。最多保留 3 个 Skill,LRU 淘汰,一次性消费,前面 07 题已经详细分析过设计原因。
多个 Skill 之间冲突怎么办
目前 PaiCLI 没有显式的 Skill 优先级机制。多个 Skill 同时存在于缓冲区时,按加载顺序排列,LLM 根据当前任务的上下文自行判断参考哪个 Skill 的指引。
这种设计依赖 LLM 的语义判断能力,在实际使用中效果可以接受,但如果两个 Skill 对同一操作给出矛盾的建议(比如一个说用 web_fetch,另一个说用浏览器),LLM 可能会在两者之间摇摆。
后续可以考虑在 Skill 的 frontmatter 里增加优先级字段,或者在 SKILL.md 里明确声明适用边界,减少交叉覆盖。
怎么衡量一个 Skill 的效果
Skill 的效果衡量比 Prompt 更难量化,因为它不直接产出结果,而是间接影响 LLM 的工具选择和决策质量。
目前可行的做法是对比“加载 Skill 前后”的任务完成率和工具调用准确率。
比如 web-access Skill 的效果,可以通过统计“LLM 是否选对了 web_fetch 和浏览器”、“是否遵循了 snapshot 优先于 screenshot 的规则”来评估。更系统的做法是建立场景化的测试用例集,定期回归验证 Skill 内容的有效性。